연결(Concatenation):
- pd.concat() 함수를 사용하여 데이터프레임을 수직 또는 수평으로 연결합니다.
- 이 방법은 인덱스나 열이 동일한 데이터프레임을 연결할 때 유용합니다.
# 데이터 만들기
data_one = {'A': ['A0', 'A1', 'A2', 'A3'],'B': ['B0', 'B1', 'B2', 'B3']}
data_two = {'C': ['C0', 'C1', 'C2', 'C3'], 'D': ['D0', 'D1', 'D2', 'D3']}
# 데이터프레임으로 변환
one = pd.DataFrame(data_one)
two = pd.DataFrame(data_two)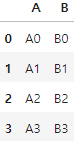

# concat을 사용하여 데이터 프레임 합치기, axis=0 행을 기준으로 합치기
axis0 = pd.concat([one,two],axis=0)
# concat을 사용하여 데이터 프레임 합치기, axis=1 열을 기준으로 합치기
axis1 = pd.concat([one,two],axis=1)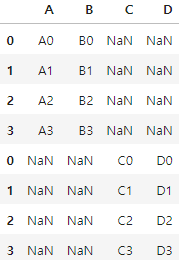
행을 기준으로 합쳐 Nan값이 들어가게 되어있습니다.
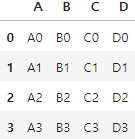
열을 기준으로 합쳐서 Nan값 없이 출력이 됩니다.
이번에는 같은 컬럼인 경우를 보겠습니다.
two.columns = one.columns
pd.concat([one,two])
병합(Merging):
- pd.merge() 함수를 사용하여 두 데이터프레임을 공통 열(키)을 기준으로 결합합니다.
- SQL의 JOIN과 유사한 방식으로, 다양한 유형의 병합을 지원합니다 (내부, 외부, 왼쪽, 오른쪽 조인 등).
registrations = pd.DataFrame({'reg_id':[1,2,3,4],'name':['Andrew','Bobo','Claire','David']})
logins = pd.DataFrame({'log_id':[1,2,3,4],'name':['Xavier','Andrew','Yolanda','Bobo']})
registrations해당 코드 또한 registrations, logins를 데이터프레임으로 만드느 함수 입니다.
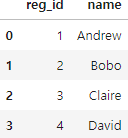

조인(Joining):
- DataFrame.join() 메서드를 사용하여 데이터프레임의 인덱스를 기준으로 다른 데이터프레임과 결합합니다.
인덱스를 기준으로 단순한 결합을 할 때 사용됩니다.다양한 옵션:
- 각 결합 방법에는 여러 가지 옵션이 있어, 결합할 때 어떤 방식으로 처리할지를 세부적으로 조정할 수 있습니다.
INNER JOIN
# sql inner join과 마찬가지로 name에서 같은 값만 있는 데이터를 가져오고 합칩니다.
pd.merge(registrations,logins,how='inner',on='name')
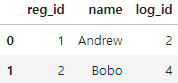
만약 하나의 열 이름만 일치하면, Pandas는 키 열(on 매개변수)을 자동으로 찾아낼 수 있습니다.
LEFT JOIN
# Left join을 사용하였으며, 왼쪽(registrations)의 값과 오른쪽(logins)값과
# 겹치는 모든 데이터를 가져옵니다.
pd.merge(registrations,logins,how='left')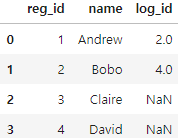
- 그래서 name에서 겹치지 않는 구간은 reg_id는 잘 나오지만 log_id는 NaN값으로 나오는 것을 확인 할 수 있습니다.
RIGHT JOIN
# right join은 left조인과는 반대라 보시면 됩니다.
pd.merge(registrations,logins,how='right')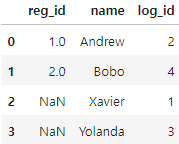
OUTER JOIN
- 좌측 테이블(Left Table)이나 우측 테이블(Right Table) 중 어느 쪽에든 존재하는 모든 정보를 맞춥니다.
- 즉, 로그 테이블과 등록 테이블에 있는 모든 사람을 보여줍니다. 누락된 정보는 NaN으로 채워집니다.
pd.merge(registrations,logins,how='outer')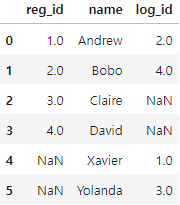
인덱스나 열 기준으로 조인하기
- left_on, right_on, left_index, right_index의 조합을 사용하여 열이나 인덱스를 서로 병합합니다.
- 우선 인덱스에 값을 설정하겠습니다.(set_index)
# name값을 인덱스로 변경합니다.
registrations = registrations.set_index("name")
registrations
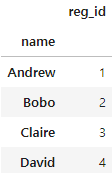
- 위의 그림과 같이 기존에는 인덱스가 0,1,2,3으로 구성되었으나, 현재는 name의 값으로 구성된 것으로 바뀐 것을 볼 수 있습니다.
인덱스를 기준으로 merge하기
pd.merge(registrations,logins,left_index=True,right_on='name')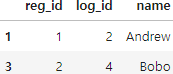
- left_index=True:
- registrations 데이터프레임의 인덱스를 조인 키로 사용하겠다는 의미입니다. 즉, registrations 데이터프레임의 인덱스 값이 조인에 사용됩니다.
- right_on='name':
- logins 데이터프레임의 'name' 열을 조인 키로 사용하겠다는 의미입니다. 즉, logins 데이터프레임의 'name' 열의 값이 조인에 사용됩니다.
- 따라서 이 명령어는 registrations 데이터프레임의 인덱스와 logins 데이터프레임의 'name' 열을 기준으로 두 데이터프레임을 병합합니다.
registrations.columns = ['reg_name','reg_id']
pd.merge(registrations,logins,left_on='reg_name',right_on='name')- 먼저 registrations의 컬럼이름을 바꿔줍니다.
- reg_name과 logins의 name을 기준으로 두 데이터 프레임을 결합합니다.
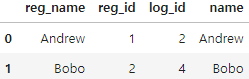
- 삭제하고싶은 컬럼이 있다면 drop을 사용하면 됩니다.
pd.merge(registrations,logins,left_on='reg_name',right_on='name').drop('reg_name',axis=1)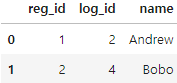
Pandas는 중복 열 있을 경우
- Pandas에서 두 개 이상의 데이터프레임을 병합할 때, 같은 이름을 가진 열이 두 데이터프레임에 모두 존재하는 경우, Pandas는 중복된 열 이름에 대해 자동으로 태그를 추가합니다.
registrations.columns = ['name','id']
logins.columns = ['id','name']
# _x is for left
# _y is for right
pd.merge(registrations,logins,on='name')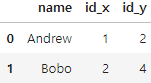
- 그리고 자동으로 입력된 id_x와 id_y의 값을 바꾸고 싶을 때는 suffixes 옵션을 사용하면 됩니다.
pd.merge(registrations,logins,on='name',suffixes=('_reg','_log'))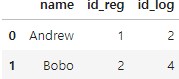
이상입니다.
'Data Analyst > ML' 카테고리의 다른 글
| ML - PANDAS(Pivot-Tables) (0) | 2024.09.10 |
|---|---|
| ML - PANDAS(Text Methods for String Data) (0) | 2024.09.03 |
| ML - PANDAS(Useful Methods) - 2 (0) | 2024.08.31 |
| ML - PANDAS(Useful Method) - 1 (0) | 2024.08.31 |
| ML - PANDAS(Condition-Filtering) (0) | 2024.08.29 |
연결(Concatenation):
- pd.concat() 함수를 사용하여 데이터프레임을 수직 또는 수평으로 연결합니다.
- 이 방법은 인덱스나 열이 동일한 데이터프레임을 연결할 때 유용합니다.
# 데이터 만들기
data_one = {'A': ['A0', 'A1', 'A2', 'A3'],'B': ['B0', 'B1', 'B2', 'B3']}
data_two = {'C': ['C0', 'C1', 'C2', 'C3'], 'D': ['D0', 'D1', 'D2', 'D3']}
# 데이터프레임으로 변환
one = pd.DataFrame(data_one)
two = pd.DataFrame(data_two)
# concat을 사용하여 데이터 프레임 합치기, axis=0 행을 기준으로 합치기
axis0 = pd.concat([one,two],axis=0)
# concat을 사용하여 데이터 프레임 합치기, axis=1 열을 기준으로 합치기
axis1 = pd.concat([one,two],axis=1)행을 기준으로 합쳐 Nan값이 들어가게 되어있습니다.
열을 기준으로 합쳐서 Nan값 없이 출력이 됩니다.
이번에는 같은 컬럼인 경우를 보겠습니다.
two.columns = one.columns
pd.concat([one,two])병합(Merging):
- pd.merge() 함수를 사용하여 두 데이터프레임을 공통 열(키)을 기준으로 결합합니다.
- SQL의 JOIN과 유사한 방식으로, 다양한 유형의 병합을 지원합니다 (내부, 외부, 왼쪽, 오른쪽 조인 등).
registrations = pd.DataFrame({'reg_id':[1,2,3,4],'name':['Andrew','Bobo','Claire','David']})
logins = pd.DataFrame({'log_id':[1,2,3,4],'name':['Xavier','Andrew','Yolanda','Bobo']})
registrations해당 코드 또한 registrations, logins를 데이터프레임으로 만드느 함수 입니다.
조인(Joining):
- DataFrame.join() 메서드를 사용하여 데이터프레임의 인덱스를 기준으로 다른 데이터프레임과 결합합니다.
인덱스를 기준으로 단순한 결합을 할 때 사용됩니다.다양한 옵션:
- 각 결합 방법에는 여러 가지 옵션이 있어, 결합할 때 어떤 방식으로 처리할지를 세부적으로 조정할 수 있습니다.
INNER JOIN
# sql inner join과 마찬가지로 name에서 같은 값만 있는 데이터를 가져오고 합칩니다.
pd.merge(registrations,logins,how='inner',on='name')
만약 하나의 열 이름만 일치하면, Pandas는 키 열(on 매개변수)을 자동으로 찾아낼 수 있습니다.
LEFT JOIN
# Left join을 사용하였으며, 왼쪽(registrations)의 값과 오른쪽(logins)값과
# 겹치는 모든 데이터를 가져옵니다.
pd.merge(registrations,logins,how='left')- 그래서 name에서 겹치지 않는 구간은 reg_id는 잘 나오지만 log_id는 NaN값으로 나오는 것을 확인 할 수 있습니다.
RIGHT JOIN
# right join은 left조인과는 반대라 보시면 됩니다.
pd.merge(registrations,logins,how='right')
OUTER JOIN
- 좌측 테이블(Left Table)이나 우측 테이블(Right Table) 중 어느 쪽에든 존재하는 모든 정보를 맞춥니다.
- 즉, 로그 테이블과 등록 테이블에 있는 모든 사람을 보여줍니다. 누락된 정보는 NaN으로 채워집니다.
pd.merge(registrations,logins,how='outer')
인덱스나 열 기준으로 조인하기
- left_on, right_on, left_index, right_index의 조합을 사용하여 열이나 인덱스를 서로 병합합니다.
- 우선 인덱스에 값을 설정하겠습니다.(set_index)
# name값을 인덱스로 변경합니다.
registrations = registrations.set_index("name")
registrations
- 위의 그림과 같이 기존에는 인덱스가 0,1,2,3으로 구성되었으나, 현재는 name의 값으로 구성된 것으로 바뀐 것을 볼 수 있습니다.
인덱스를 기준으로 merge하기
pd.merge(registrations,logins,left_index=True,right_on='name')
- left_index=True:
- registrations 데이터프레임의 인덱스를 조인 키로 사용하겠다는 의미입니다. 즉, registrations 데이터프레임의 인덱스 값이 조인에 사용됩니다.
- right_on='name':
- logins 데이터프레임의 'name' 열을 조인 키로 사용하겠다는 의미입니다. 즉, logins 데이터프레임의 'name' 열의 값이 조인에 사용됩니다.
- 따라서 이 명령어는 registrations 데이터프레임의 인덱스와 logins 데이터프레임의 'name' 열을 기준으로 두 데이터프레임을 병합합니다.
registrations.columns = ['reg_name','reg_id']
pd.merge(registrations,logins,left_on='reg_name',right_on='name')- 먼저 registrations의 컬럼이름을 바꿔줍니다.
- reg_name과 logins의 name을 기준으로 두 데이터 프레임을 결합합니다.
- 삭제하고싶은 컬럼이 있다면 drop을 사용하면 됩니다.
pd.merge(registrations,logins,left_on='reg_name',right_on='name').drop('reg_name',axis=1)
Pandas는 중복 열 있을 경우
- Pandas에서 두 개 이상의 데이터프레임을 병합할 때, 같은 이름을 가진 열이 두 데이터프레임에 모두 존재하는 경우, Pandas는 중복된 열 이름에 대해 자동으로 태그를 추가합니다.
registrations.columns = ['name','id']
logins.columns = ['id','name']
# _x is for left
# _y is for right
pd.merge(registrations,logins,on='name')- 그리고 자동으로 입력된 id_x와 id_y의 값을 바꾸고 싶을 때는 suffixes 옵션을 사용하면 됩니다.
pd.merge(registrations,logins,on='name',suffixes=('_reg','_log'))
이상입니다.
'Data Analyst > ML' 카테고리의 다른 글
| ML - PANDAS(Pivot-Tables) (0) | 2024.09.10 |
|---|---|
| ML - PANDAS(Text Methods for String Data) (0) | 2024.09.03 |
| ML - PANDAS(Useful Methods) - 2 (0) | 2024.08.31 |
| ML - PANDAS(Useful Method) - 1 (0) | 2024.08.31 |
| ML - PANDAS(Condition-Filtering) (0) | 2024.08.29 |