Data 원본 출처
- Target Data(CSV): 역대(1976-2008) 하계 올림픽 메달리스트에 대한 정보
- 올림픽 메달 취소 등 반영 안되어있음
- 복식/단체 종목의 선수 수, 당시 메달 수여 룰, 메달 취소 및 승격/승계 등의 실제 메타데이터가 없이는 확인 어려움
1단계: Load Data & Preprocessing
3-1. Load Target Data
문제 1-1) Target Data 가져오기 (10점)
- 위에 제시된 링크 혹은 datas 폴더에 있는 데이터(Summer-Olympic-medals-1976-to-2008.csv)를 Pandas DataFrame으로 읽어 오세요.
# 1-1
import pandas as pd
# 채점을 위한 코드입니다. 반드시 실행해주세요.
from grading import *
df_path = 'C:/Users/min99/EDA3/datas/Summer-Olympic-medals-1976-to-2008.csv'
df_target = pd.read_csv(df_path, encoding='cp949', encoding_errors='ignore')
check_01_01(df_target)이 문제에서 cp949를 통해 encoding을 시도 하였었습니다. 하지만 계속 같은 오류가 발생 하였습니다.
그래서 코드를 확인한 결과 encoding은 잘 이루어진 것 같았습니다.
이 때 오류를 무시하면 될 거 같아서 encoding_errors = 'ignore'을 활용하였습니다.
문제 1-2) Preprocessing: missing data 처리 (10점)
- 1-1에서 읽은 Data에는 missing data가 있습니다. missing data를 확인하고 처리하세요.
- 조건1: missing data가 있다면, 해당 row(행)를 삭제(drop)하세요
- 조건2: Index를 초기화(reset)하고, 기존 Index는 삭제(drop)하세요.
# 1-2
df_target.dropna(inplace=True)
df_target.reset_index(drop=True)
# df_target.head()
check_01_02(df_target)dropna() 함수를 활용하여 Nan값이 있는 행들을 모두 삭제하였고 reset_index()를 할용하여 인덱스를 초과해주는 작업을 하였습니다.
문제 1-3) Preprocessing: Data Type 정리 (10점)
- 1-2에서 만든 DataFrame을 아래의 조건에 따라 데이터의 타입을 확인하고 변경해주세요.
- 조건1: float data는 int로 변경해주세요.
- 조건2: float data외의 모든 데이터가 string 인지 확인해주세요.
# 1-3
df_target['Year']=df_target['Year'].astype('int64')
df_target.info()
check_01_03(df_target)처음 Year 컬럼에 있던 값들의 데이터타입은 float형으로 확인 되었습니다. 그래서 ,astype('int64') 함수를 이용하여 int형으로 바꿔 주었습니다.
2단계: 원하는 Data로 가공하기
문제 2-1) 2008년 대한민국 메달리스트 찾기 (15점)
- 문제 1에서 만든 DataFrame을 이용하여 2008년 베이징 올림픽 양궁 종목에서 금메달을 획득한 선수들을 찾아보세요.
- 조건1: 2008년 베이징 올림픽 양궁 종목의 금메달리스트만 있는 DataFrame을 만들어 주세요
- 예시: 1992년 바르셀로나 올림픽 양궁 금메달리스트 DataFrame
- 조건1: 2008년 베이징 올림픽 양궁 종목의 금메달리스트만 있는 DataFrame을 만들어 주세요
# 2-1
import copy
df_archery = copy.deepcopy(df_target[(df_target['Sport'] == 'Archery') & (df_target['Medal'] == 'Gold') & (df_target['City'] == 'Beijing') & (df_target['Country_Code'] == 'KOR')])
check_02_01(df_archery)위의 문제의 모든 조건을 만족 시키기 위해 논리연산자 '&'을 사용하여 개최지, 양궁, 금메달, 한국선수의 해당하는 값들을 가져와 df_archery에 조건에 부합하는 데이터프레임을 저장하였습니다.
문제 2-2) 대한민국 역대(1976-2008) 하계 올림픽 메달 획득 내역 확인(15점)
- 문제 1에서 만든 DataFrame과 Pandas 기능을 활용하여 아래 예시와 같은 형태의 대한민국 역대 메달 획득 내역을 만들어주세요.
- 조건1: Index는 Year - Medal로 보여주세요(아래 예시 참고)
- 조건2: Index에서 Year는 내림차순, Medal은 Gold-Silver-Bronze 순으로 보여주세요(아래 예시 참고)
- 조건1: Index는 Year - Medal로 보여주세요(아래 예시 참고)
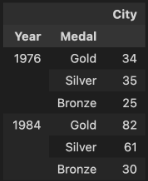
- hint1: 앞서 이야기 한 바와 같이, 메달 숫자는 복식/단체 종목을 감안하여 선수명(Athlete)과 성별(Gender)를 제외한 내용이 일치할 경우 같은 경기에서 획득한 메달로 간주하시면 됩니다.
- hint2: 내용이 일치하는 데이터를 삭제하기 위한 방법은 drop_duplicate, groupby, pivot_table 등 다양한 방법이 있습니다.
- hint3: Medal Index의 정렬 순서를 'Gold'-'Silver'-'Bronze'로 하기 위해서 sort_index의 'key' argument에 dictionary를 활용할 수 있습니다. - 이 외에 sort_index의 다른 arguments도 확인해 보세요
# 2-2
import copy
medal_mapping = {'Gold':1, 'Silver':2, 'Bronze':3}
df_drop_column = df_target.drop_duplicates(subset=['City', 'Year', 'Sport', 'Discipline', 'Event', 'Country_Code', 'Country', 'Event_gender', 'Medal'])
df = df_drop_column[df_drop_column['Country_Code'] == 'KOR']
df = df.groupby(['Year', 'Medal'])['City'].count().to_frame().reset_index()
df['Medal_order'] = df['Medal'].map(medal_mapping)
df = df.sort_values(by=['Year', 'Medal_order']).drop(columns='Medal_order').set_index(['Year', 'Medal'])
df_kor = copy.deepcopy(df)
check_02_02(df_kor)해당 문제를 풀면서 꽤나 많은 시간을 지체하였었습니다. 그 이유는 우선 group by를 통해 year와 medal을 묶고 집계함수 count를 사용하여 표를 출력하는 것까지는 쉽게 되었습니다.
하지만 문제는 gold, silver, bronze 순으로 해야 하는 것이였습니다. 그래서 hint에 있는 sort_index()의 'key' argument를 활용하였으나, 계속 위의 예시 그림처럼 되는 것이 아닌 year의 그룹핑이 깨지는 현상이 발생하였습니다.
결국, 해결책을 찾지 못하여 mapping() 함수와 sort_values() 함수를 사용하여 문제를 풀었습니다. 이제 코드 설명을 하겠습니다.
- 1. hint 1의 조건을 맞추기 위해 우선 선수명(Athlete)과 성별(Gender)를 제외한 컬럼들의 중복값이 있는 값들을 drop하기 위해 drop_duplicates(subset=중복컬럼 정하기) 함수 활용하여 새로운 데이터 프레임(df_drop_column)을 만들어 주었습니다.
- 한국 선수들의 내용만 가져오기 위하여 df_drop_column 데이터 프레임의 Country_Code 컬럼에서 KOR만 지정하였습니다. 그리고 새로운 데이터프레임(df)에 저장하였습니다.
- 이제 groupby() 함수를 이용하여 Year와 Medal을 기준으로 그룹핑을 해주었습니다. 그리고 Count()를 사용하여 해당 년도의 대한민국 선수가 금메달 개수, 은메달 개수, 동메달 개수가 나오도록 만들어 주었습니다.
- to_frame()을 활용하여 Series로 출력되는 값을 데이터 프레임으로 바꿔 주었습니다.
- reset_index를 통해 그룹핑을 초기화 해주었습니다.(초기화를 해야 4번 방법을 활용할 수 있음.)
- 새로운 컬럼(['Medal_order'])을 만들어 map()함수를 활용하여 'Gold'인 행은 1을 'Silver'인 행은 2를 'Bronze'인 행은 3을 넣어 주었습니다. (Medal_order, Year 컬럼을 기준으로 정렬하기 위해 만들어 주었음.)
- Medal_order, Year 컬럼을 기준으로 sort_values()함수를 활용하여 정렬해준 뒤 이제 필요 없는 Medal_order 컬럼을 drop 해주고 인덱스를 ['Year', 'Medal']로 설정해주었습니다.
물론 더 쉬운 방법이 존재할 거 같습니다. 그래서 좀 더 코딩을 해보려 합니다.
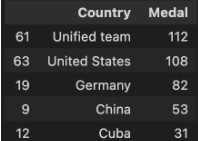
문제 2-3) 1996년 애틀란타 올림픽 총 메달 개수 기준 상위 10개 국가 확인하기(20점)
- 문제 1에서 만든 DataFrame과 Pandas 기능을 활용하여 아래 예시와 같은 형태의 총 메달 개수 기준 상위 10개국 내역을 만들어주세요.
- 조건1: Index는 앞선 1단계에서 Preprocessing한 Data의 Index 그대로 나두어 주세요.
- 조건2: 총 메달 개수로 오름차순 정렬 후 상위 10개 국가만 나타내는 DataFrame을 만드세요.
- 조건3: 결과 DataFrame의 Columns은 ['Country', 'Medal'] 입니다.
- 조건1: Index는 앞선 1단계에서 Preprocessing한 Data의 Index 그대로 나두어 주세요.
# 2-3
import copy
# 중복 선수명(Athlete)과 성별(Gender)를 제외한 내용
df_drop_column2 = df_target.drop_duplicates(subset=['City', 'Year', 'Sport', 'Discipline', 'Event', 'Country_Code', 'Country', 'Event_gender', 'Medal'])
df_drop_column2 = df_drop_column2[df_drop_column2['Year'] == 1996]
df2 = df_drop_column2.groupby(['Country'])['Medal'].count().to_frame().reset_index()
df2 = df2.sort_values(by='Medal', ascending=False).head(10)
df_rank_10 = copy.deepcopy(df2)
check_02_03(df_rank_10)해당 문제는 1996년 애틀란타 올림픽의 총 매달 개수를 가져오는 것이므로 Year 컬럼의 값이 1996인 데이터의 값을 가져와주어야 합니다. (1996을 읽지 못하고 계속 실행하는 바람에 푸는데 시간이 좀 걸렸습니다.)
이제 또 국가 마다의 총 메달 수를 계산하기 위해서 groupby를 통해 Country를 기준으로 그룹핑 해주고 Medal의 값만 궁금하니 컬럼에 'Medal'을 넣고 Count() 계산을 한 뒤 위의 예시 처럼 표현하기 위해 reset_index()를 사용해 줍니다.
조건 2를 충족 시키기 위해 sort_values()의 'ascending = False'를 활용하여 내림차순 해준뒤 상위 10개 데이터만 가져오도록 head(10)함수를 사용하여 저장하였습니다.
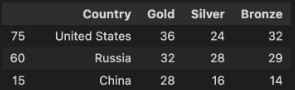
문제 2-4) 1996년 애틀란타 올림픽 금매달 개수 기준 상위 10개 국가 확인하기(20점)¶
- 문제 1에서 만든 DataFrame과 Pandas 기능을 활용하여 아래 예시와 같은 형태의 금메달 개수 기준 상위 10개국 내역을 만들어주세요.
- 조건1: 'Gold', 'Silver', 'Bronze' 컬럼을 만들고, 해당 Row(행)의 Medal 이 Gold면 'Gold' 컬럼에 1, Silver면 'Silver' 컬럼에 1, 'Bronze'면 'Bronze'컬럼에 1을 입력하세요
- 추후 아래 예시와 같은 형태로 DataFrame을 만들기 위한 작업입니다. 적당한 순서에 맞추어 해당 작업을 하시면 되고, 혹시 이 작업이 필요 없을 경우 안하셔도 무방합니다.
- 조건1: 'Gold', 'Silver', 'Bronze' 컬럼을 만들고, 해당 Row(행)의 Medal 이 Gold면 'Gold' 컬럼에 1, Silver면 'Silver' 컬럼에 1, 'Bronze'면 'Bronze'컬럼에 1을 입력하세요
- 조건2: Index는 앞선 1단계에서 Preprocessing한 Data의 Index 그대로 나두어 주세요.
- 조건3: 금메달 개수로 내림차순 정렬 후 상위 10개 국가만 나타내는 DataFrame을 만드세요. - 만약 금메달 개수가 같다면, 은메달 개수가 많은 국가가 더 높은 순위이며 은메달 개수도 같다면 동메달 개수가 더 많은 국가가 상위입니다.
- 조건4: 결과 DataFrame의 Columns은 ['Country', 'Gold', 'Silver', 'Bronze'] 입니다.
- 예시: 1992년 바르셀로나 올림픽 총 메달 개수에 따른 상위 10개 국가
# 2-4
df_drop_column2 = df_target.drop_duplicates(subset=['City', 'Year', 'Sport', 'Discipline', 'Event', 'Country_Code', 'Country', 'Event_gender', 'Medal'])
df3 = df_drop_column2[df_drop_column2['Year'] == 1996]
df3_pivot = df3.pivot_table(index='Country', columns='Medal', aggfunc='size', fill_value=0).reset_index()
df3_pivot.columns.name = None
df3_pivot[['Gold','Silver','Bronze']] = df3_pivot[['Gold','Silver','Bronze']].astype(int)
df3_pivot = df3_pivot.sort_values(by=['Gold','Silver','Bronze'], ascending=False)
new_columns = ['Country','Gold','Silver','Bronze']
df_rank_10 = df3_pivot[new_columns].head(10)
check_02_04(df_rank_10)이 문제를 활용하면서 groupby를 통해 Country와 Medal을 동시에 묶고 count를 사용하려 했으나, 그렇게 하면 코드의 내용이 복잡해지고 조건 1을 만족해서 하기에는 비효율적이라 생각되어 차라리 집계함수를 count가 아닌 size를 사용하는 것으로 문제를 풀었습니다. 이제 코드 설명을 시작하겠습니다.
- pivot_table에서 index는 Country, columns는 Medal을 넣어주고 집계함수는 size를 넣어 주었습니다.
- 국가마다 금,은,동 메달을 받지 못했을 수도 있습니다. 그 경우 pivot_table을 할 시 Nan값으로 출력되기 때문에 fill_value=0을 통해 Nan 값들은 0으로 설정해주었습니다.
- 위의 예시와 같이 출력하기 위해 reset_index()를 활용하였습니다.
- 이제 df_3를 출력하면 쓸데없는 컬럼명인 Medal이 data frame에 출력되게 됩니다. 이를 없애기 위해 .columns.name = None을 활용 하여 컬럼명을 없애주는 작업을 해주었습니다
- 그리고 Gold, Silver, Bronze 컬럼의 값들이 float형으로 출력되는 것이 확인되어 astype()을 활용하여 int형으로 변환해주었습니다.
- 조건 3의 내용을 충족시키기 위해 sort_value()를 통해 정렬해주었습니다.
- 컬럼의 내용이 중구난방하게 출력되어 매우 간단하게 기존에 있는 컬럼명들을 정렬해서 작성하고 head()를 통해 상위 10개 데이터만 가져왔습니다.

느낀점
이렇게 해서 EDA 3테스트의 문제들을 모두 풀어보는 시간이 되었습니다. 중간중간 마다 시간이 오래 걸린 것들은 구글링을 통해 풀어보기도 하였습니다. 이렇게 하다보니 역시 아직 부족한 점이 많은 것을 느끼게 되었습니다. 하지만 확실히 혼자서 문제를 풀어보는 경험을 해보니 dataframe에 적용하는 함수들이 점점 손에 익고 실력이 향상되는 것을 느낄 수 있었습니다.
이 글은 제로베이스 데이터 분석 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.
'Project > EDA 연습' 카테고리의 다른 글
| [Zero-base] EDA 5회차 테스트 (10) | 2024.10.02 |
|---|---|
| [Zero-base] EDA 4회차 테스트 (1) | 2024.09.27 |