RANK 함수
RANK 함수는 특정 컬럼의 값을 기준으로 순위를 매깁니다. 이 때 동일한 값이 있을 경우 같은 순위를 부여하지만, 다음 순위는 건너뜁니다.
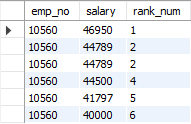
위 테이블에서 RANK() 함수는 두 번째와 세 번째 행에 같은 순위 2을 부여한 후, 네 번째 행에는 순위를 건너뛰어 4를 부여합니다.
사용 예시:
select
emp_no,
salary,
rank() over w as rank_num -- rank 함수 사용
from
salaries
where emp_no = 10560
window w as (partition by emp_no order by salary desc);DENSE_RANK 함수
DENSE_RANK 함수도 순위를 매기지만, 순위가 건너뛰지 않는 점이 RANK 함수와 다릅니다. 동일한 값이 있을 경우 같은 순위를 부여하지만, 그 다음 순위는 건너뛰지 않고 바로 이어집니다.
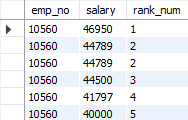
위 테이블에서 RANK() 함수는 두 번째와 세 번째 행에 같은 순위 2을 부여한 후, 네 번째 행에는 순위를 건너뛰지 않고 3을 부여합니다.
사용 예시:
-- rank()함수 사용과 다를게 없다.
select
emp_no,
salary,
dense_rank() over w as rank_num
from
salaries
where emp_no = 10560
window w as (partition by emp_no order by salary desc);LAG 함수
LAG 함수는 이전 행의 값을 가져옵니다. 데이터의 흐름에서 이전 값을 비교하거나 참조해야 할 때 유용합니다. 기본적으로 바로 이전 행의 값을 반환하며, offset을 설정해 몇 번째 이전 값을 참조할지 결정할 수 있습니다.
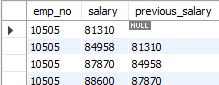
위 테이블에서 LAG 함수 사용으로 첫번째 행을 보면 10505의 값이 previous_salary 컬럼에는 null이 출력된 것으로 보입니다. 그 이유는 salary 컬럼의 첫 번째 값 이전의 값이 없기 때문입니다.
사용 예시:
select
emp_no,
salary,
lag(salary) over w as previous_salary
from
salaries
where emp_no between 10500 and 10600 and salary >= 80000
window w as (partition by emp_no order by salary);
LAG 함수의 offset 함수 사용도 보여드리겠습니다.
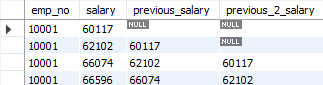
위 테이블과 같이 이전의 두 번째 값을 출력하는 것을 확인 할 수 있습니다.
사용 예시:
select
emp_no,
salary,
lag(salary) over w as previous_salary,
lag(salary, 2) over w as previous_2_salary,
from
salaries
window w as (partition by emp_no order by salary)
limit 1000;LEAD 함수
LEAD 함수는 LAG와 반대로 다음 행의 값을 가져옵니다. 데이터의 흐름에서 다음 값을 비교하거나 참조할 때 사용됩니다. 마찬가지로 offset을 설정할 수 있습니다.
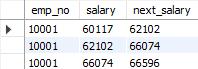
위 테이블에서 LAG 함수 사용으로 첫번째 행을 보면 10505의 값은 60117이고 LEAD 함수를 사용하여 만든 열인 next_salary컬럼에는 salary 행의 두번째 값인 62102가 출력된 것을 확인 하실 수 있습니다.
사용 예시:
select
emp_no,
salary,
lead(salary) over w as next_salary
from
salaries
window w as (partition by emp_no order by salary)
limit 1000;LEAD 함수 또한 그동안 봤던 ROW_NUMBER(), RANK() 함수와는 달리 함수 괄호 안에
LEAD(column_name : 어떤 컬럼에서 추출할 것인지, offset : 몇 번째 값부터 가져올 것인지) over ~
이처럼 넣고 사용해주시면 됩니다.
이번에는 offset을 활용한 예시를 보여드리겠습니다.
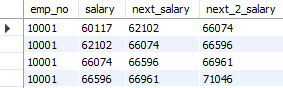
사용 예시:
select
emp_no,
salary,
lead(salary) over w as next_salary,
lead(salary, 2) over w as next_2_salary -- offset = 2 사용
from
salaries
window w as (partition by emp_no order by salary)
limit 1000;위의 예시 처럼 사용해주시면 됩니다.
자료와 실습 도움을 준 강의입니다. (Udemy: SQL - MySQL for Data Analytics and Business Intelligence)
이상입니다.
'Data Analyst > SQL' 카테고리의 다른 글
| [SQL] CASE 사용하여 문제 풀기 (Type of Triangle) (0) | 2024.10.10 |
|---|---|
| [SQL] GROUP BY 사용하여 문제풀기 (Top Earners) (0) | 2024.10.09 |
| SQL - Window Functions (ROW_NUMBER) (0) | 2024.09.20 |
| SQL - Index, Case Statement (1) | 2024.09.17 |
| SQL - Trigger (0) | 2024.09.16 |