KNeighbors Classifier (K - 최근접 이웃 분류 모델)
새로운 데이터를 분류할 때 가장 가까운 데이터 포인터들을 기반으로 결정을 내립니다.
즉, 새로운 데이터가 주어지면, 그 데이터가 속할 카테고리를 주변 이웃 데이터들과의 거리를 보고 결정합니다.
동작 원리
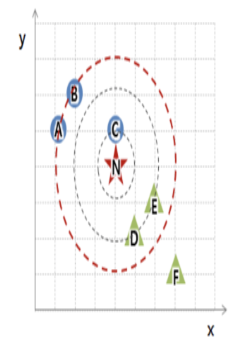
근처 이웃의 수를 결정해야 합니다. 예를 들어 k = 5라면 5 개의 이웃을 찾아 그들의 분류 결과에 따라 새로운 데이터를 분류합니다.(아래 사진 참조)
거리 계산 : 유클리드 거리 공식을 사용합니다.
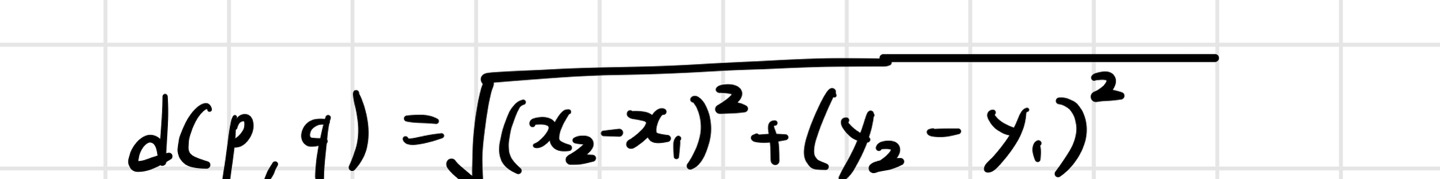
이 계산을 통해 가장 가까운 이웃 k개를 선택합니다.
그 이웃들의 카테고리가 많은 쪽이 새로운 데이터의 카테고리가 됩니다.
K-최근접 이웃 분류 모델 장단점
KNN은 매우 간단하나, 정확도가 떨어지는 편입니다.
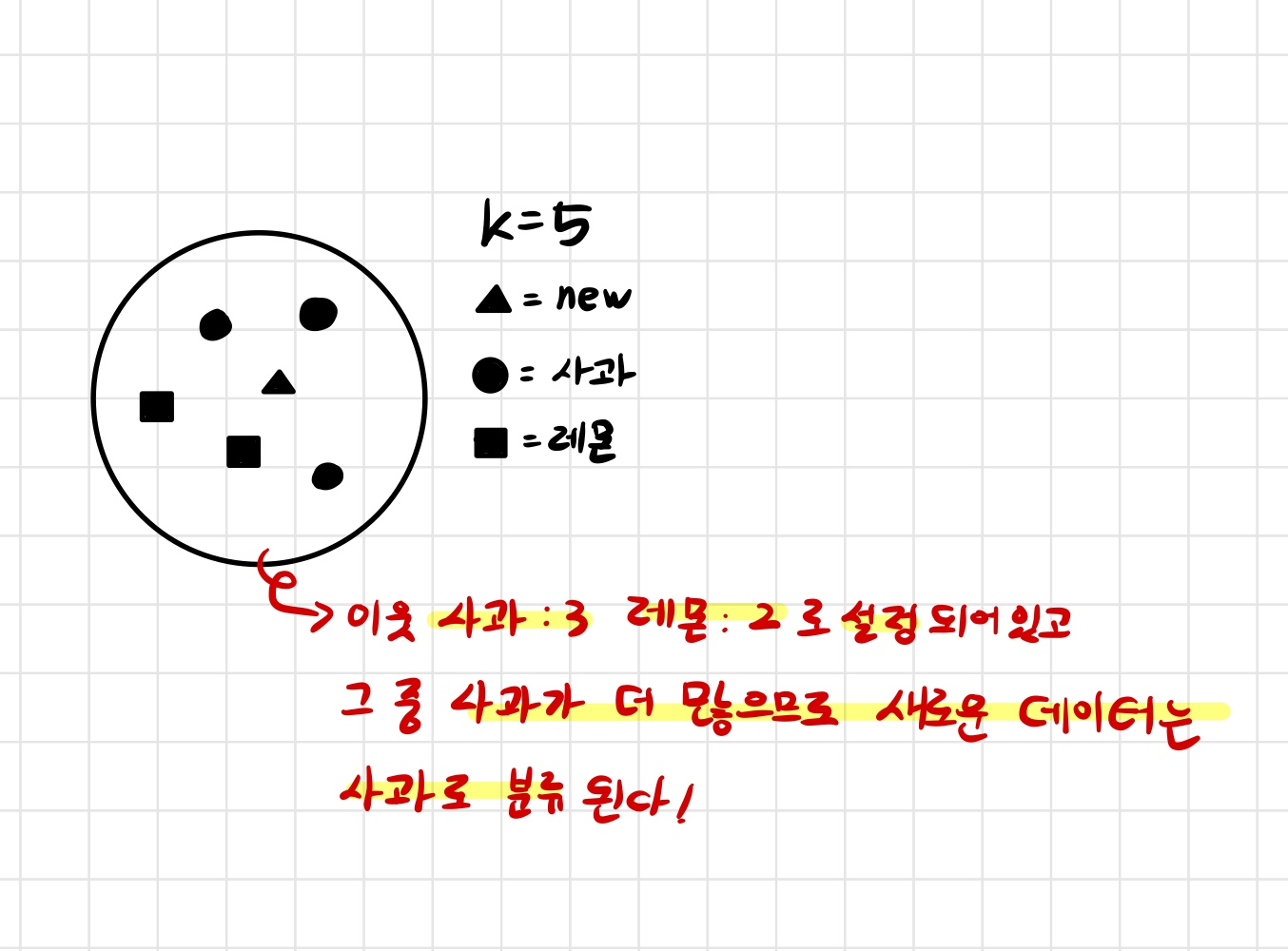
참고 그림
이번 글은 KNN의 기본 개념과 동작원리, 장단점에 대해 알아보았습니다.
다음 글은 python을 통해 KNN 모델을 사용하고 정확도를 평가해보겠습니다.
이상입니다.
'Data Analyst > ML' 카테고리의 다른 글
| [Zero-base] 앙상블 기법 - 1 (3) | 2024.10.08 |
|---|---|
| [Zero-base] KNN(KNeighbors Classifier) - 2 (0) | 2024.10.07 |
| [Zero-base] Precision and Recall (0) | 2024.10.07 |
| [Zero-base] Cross Validation(교차 검증) - 2 (0) | 2024.10.04 |
| [Zero-base] Cross Validation(교차 검증) - 1 (0) | 2024.10.04 |
KNeighbors Classifier (K - 최근접 이웃 분류 모델)
새로운 데이터를 분류할 때 가장 가까운 데이터 포인터들을 기반으로 결정을 내립니다.
즉, 새로운 데이터가 주어지면, 그 데이터가 속할 카테고리를 주변 이웃 데이터들과의 거리를 보고 결정합니다.
동작 원리
근처 이웃의 수를 결정해야 합니다. 예를 들어 k = 5라면 5 개의 이웃을 찾아 그들의 분류 결과에 따라 새로운 데이터를 분류합니다.(아래 사진 참조)
거리 계산 : 유클리드 거리 공식을 사용합니다.
이 계산을 통해 가장 가까운 이웃 k개를 선택합니다.
그 이웃들의 카테고리가 많은 쪽이 새로운 데이터의 카테고리가 됩니다.
K-최근접 이웃 분류 모델 장단점
KNN은 매우 간단하나, 정확도가 떨어지는 편입니다.
참고 그림
이번 글은 KNN의 기본 개념과 동작원리, 장단점에 대해 알아보았습니다.
다음 글은 python을 통해 KNN 모델을 사용하고 정확도를 평가해보겠습니다.
이상입니다.
'Data Analyst > ML' 카테고리의 다른 글
| [Zero-base] 앙상블 기법 - 1 (3) | 2024.10.08 |
|---|---|
| [Zero-base] KNN(KNeighbors Classifier) - 2 (0) | 2024.10.07 |
| [Zero-base] Precision and Recall (0) | 2024.10.07 |
| [Zero-base] Cross Validation(교차 검증) - 2 (0) | 2024.10.04 |
| [Zero-base] Cross Validation(교차 검증) - 1 (0) | 2024.10.04 |