이전 글에서 했던 예측 모델에서 많은 문제가 있었습니다.
첫번째, 왜 선형 회귀 모델을 사용하였는지 모른다는 문제
두번째, 각 변수마다 이상치를 모두 확인 하지 않았던 문제
해당 문제를 이번 글에서 해결 해보겠습니다.
그리고 XGBoost와 하이퍼파라미터 튜닝 또한 해보겠습니다.
1. 왜 선형 회귀 모델을 사용하면 안될까?
우선 해당 문제는 최동원 선수의 연봉 예측 문제이고 아래의 이미지와 같이 해당 분포도를 보면 선형적인 그래프를 가지지 않습니다.
그래서 선형 회귀를 사용하는 것은 매우 좋지 않은 선택이며 성능 저하될 수 도 있다 판단 하였습니다.
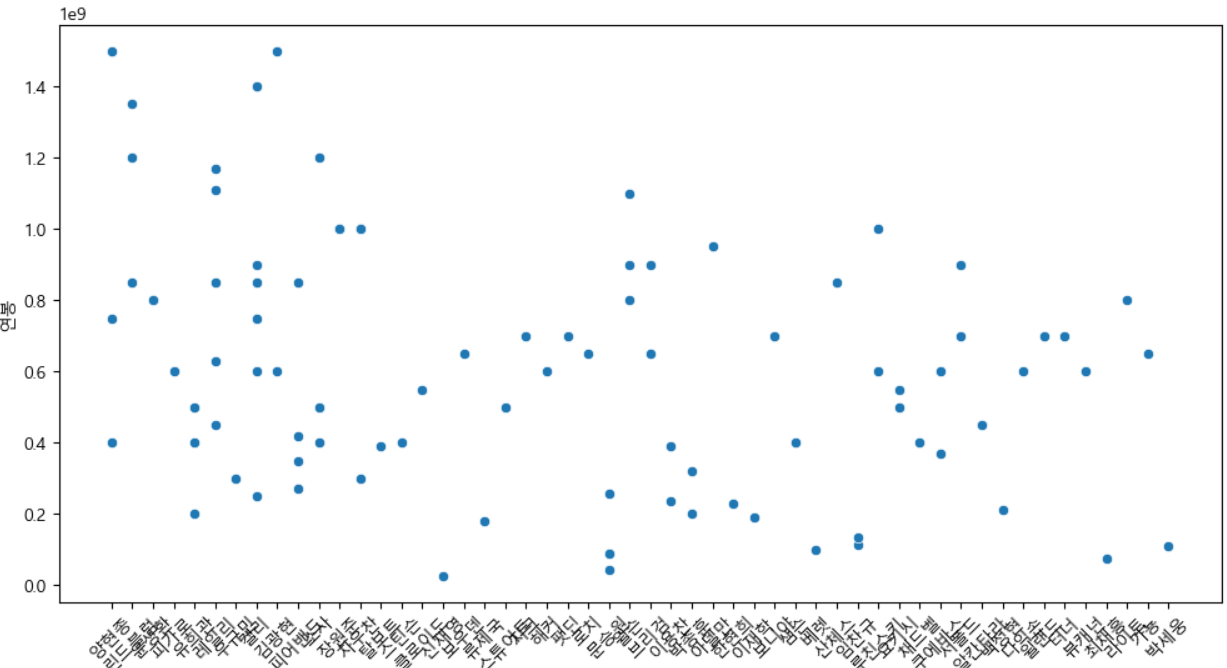
그래서 저는 차라리 비선형 관계를 잘 학습하는 앙상블 방법 중 XGBoost를 사용하여 하이퍼 파라미터 성능 조정도 하여 연봉 예측을 해보겠습니다.
2. 각 변수마다 이상치 확인하기
import matplotlib.pyplot as plt
import seaborn as sns
num_cols = baseball.drop(columns=['선수명', '팀명']).shape[1]
num_rows = (num_cols // 3) + 1 # 3개씩 한 줄에 표시
fig, axes = plt.subplots(num_rows, 3, figsize=(15, 5 * num_rows))
axes = axes.flatten()
for i,col in enumerate(baseball.drop(columns=['선수명', '팀명']).columns):
sns.boxplot(x=baseball[col], ax=axes[i])
axes[i].set_title(col)
for j in range(i + 1, len(axes)):
fig.delaxes(axes[j])
plt.tight_layout()
plt.show()이번에는 각 변수마다 이상치를 확인해보는 코드를 추가하였습니다.
그 결과 생년월일, 연봉, ERA, G, W, L, WPCT, H, HR, BB, HBP, SO, WHIP 컬럼에서 이상치가 있는 것을 확인 하였고 해당 이상치 컬럼들만 제거하여 이상치 제거 코드의 효율성을 높여 주었습니다.
3. XGBoost와 하이퍼파라미터 튜닝 이용하기
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split, GridSearchCV
from xgboost import XGBRegressor
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
X = ss.fit_transform(baseball.drop(columns=['연봉', '선수명', '팀명', 'SV', 'HLD'], axis=1))
y = baseball['연봉']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = XGBRegressor(objective='reg:squarederror', n_estimators=100)
# 하이퍼파라미터 그리드 설정
param_grid = {
'n_estimators': [100, 200, 300],
'max_depth': [3, 5, 7],
'learning_rate': [0.01, 0.1, 0.2],
'subsample': [0.6, 0.8, 1.0]
}
grid_search = GridSearchCV(estimator=model, param_grid=param_grid,
cv=5, verbose=1, n_jobs=-1) # verbose : 진행 메세지
grid_search.fit(X_train, y_train)
best_params = grid_search.best_params_
print('Best Hyperparameter:',best_params)
best_model = grid_search.best_estimator_
y_pred = best_model.predict(X_test)
# 성능 메트릭 계산
mse = mean_squared_error(y_test, y_pred)
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
# 성능 출력
print("평균 제곱 오차 (MSE):", mse)
print("평균 절대 오차 (MAE):", mae)
print("결정 계수 (R²):", r2)Best Hyperparameter: {'learning_rate': 0.01, 'max_depth': 3, 'n_estimators': 200, 'subsample': 0.8}
평균 제곱 오차 (MSE): 1.002145536728298e+17
평균 절대 오차 (MAE): 276585330.5263158
결정 계수 (R²): -0.028609756714441215결과는 매우 심각하게 나왔지만 XGBoost와 하이퍼 파라미터 튜닝을 통해 제일 오차를 줄일 수 있는 파라미터를 확인 할 수 있었습니다.
그리고 이전에 했던 내용에서의 오차가 더 적긴 했지만 그래도 해당 주제에 맞는 모델을 사용하였다는 것에 좀 더 의미를 둬야 할 것 같습니다.
그리고 최종적으로 연봉 예측을 하였지만, 연도마다 최동원 선수의 연봉들이 모두 같게 나온 문제가 발생되어 이 문제는 좀더 생각해보고 다시 해당 문제를 해결해야 할 듯 싶습니다.
좀 더 공부해서 다시 좋은 결과물로 들고 오겠습니다.
이상입니다.
'Project > Machine Learning' 카테고리의 다른 글
| Project - Instacart 데이터 물품 재구매 예측하기(RFM) (0) | 2024.11.19 |
|---|---|
| Project - Instacart 데이터 물품 재구매 예측하기 (0) | 2024.11.18 |
| [Zero-base] 최동원 선수 연봉 예측하기 - 3 (1) | 2024.10.21 |
| [Zero-base] 최동원 선수 연봉 예측하기 - 2 (0) | 2024.10.21 |
| [Zero-base] 최동원 선수 연봉 예측하기 - 1 (1) | 2024.10.18 |