꽃 잎과 꽃 밭침의 길이와 너비로 IRIS 꽃의 품종을 분류하는 모델을 만들어보자.
# 사이킷런에 있는 아이리스 꽃에 대한 데이터셋을 가져옵니다.
from sklearn.datasets import load_iris
iris = load_iris()
# 해당 iris에서 사용할 수 있는 함수들 목록을 불러옵니다.
iris.keys()위의 코드를 사용하면 iris에 관련한 데이터 셋을 가져올 수 있습니다.
그리고 keys()를 활용해 기본 정보를 볼 수 있는 함수 목록들을 볼 수 있습니다.
# 특성 : 해당 iris 품종의 꽃받침 길이, 너비 또는 꽃잎의 길이, 너비가 있는 것을 확인할 수 있습니다.
iris.feature_names
# Label : 즉 iris 품종 우리가 예측해야 할 값.('setosa', 'versicolor', 'virginica')
iris.target_names
# 위의 값의 인덱스이며 각 행의 특성에 대한 Label이 무엇인지 표현
iris.target
# 데이터들을 모두 보여줌.
iris.datakeys()함수를 사용했을 때 가능한 함수들의 일부를 사용한 것입니다.
위의 주석의 내용 처럼 해당 품종을 구별할 수 있는 특성, 어떤 품종이 있는 지, 품종들이 어떻게 들어있는지, 데이터의 모든 값들을 확인 할 수 있습니다.
# DataFrame으로 만들어주고 컬럼 명들은 feature_names를 활용하여 넣어 줍니다.
import pandas as pd
iris_pd = pd.DataFrame(iris.data, columns=iris.feature_names)
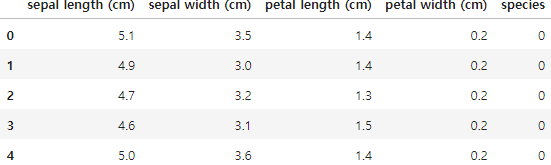
iris_pd.head()이제 본격적으로 pandas를 활용하여 iris 데이터를 DataFrame으로 변환해주고 해당 데이터에는 컬럼명이 없었으므로 feature_names를 사용하여 컬럼명을 지정해줍니다.
하지만 해당 DataFrame에는 특성만 있고 어떤 품종인지에 대한 컬럼과 값이 없습니다.
# target활용하고 새로운 컬럼 species에 넣어주기.
iris_pd['species'] = iris.target위에서 말한 문제를 target함수를 사용하여 해결해주었습니다.
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(12,6))
sns.boxplot(x='sepal length (cm)', y='species', data=iris_pd, orient='h')
# 겹치는 구간이 많아서 sepal length로 품종을 구별하기 어렵다.이번에는 boxplot을 활용하여 어떤 기준으로 품종을 나눌 지를 결정할 것입니다.
해당 boxplot을 확인해보면 sepal length로는 겹치는 구간이 매우 많아 구별하기 어려운 것으로 확인 되었습니다.

plt.figure(figsize=(12,6))
sns.boxplot(x='petal length (cm)', y='species', data=iris_pd, orient='h')
# 확연히 품종이 0번인 값은 petal length로 구별할 수 있다.이번에는 x를 petal length (cm)로 설정하고 보니 품종이 0번(setosa)인 것이 확연하게 보입니다.

이제 품종이 0번인 것은 petal length를 활용하면 확실하게 분류 할 수 있으니 나머지 1번 2번 품종에 집중하기 위해 따로 DataFrame을 만들겠습니다.
iris_12 = iris_pd[iris_pd['species'] != 0]
plt.figure(figsize=(10,4))
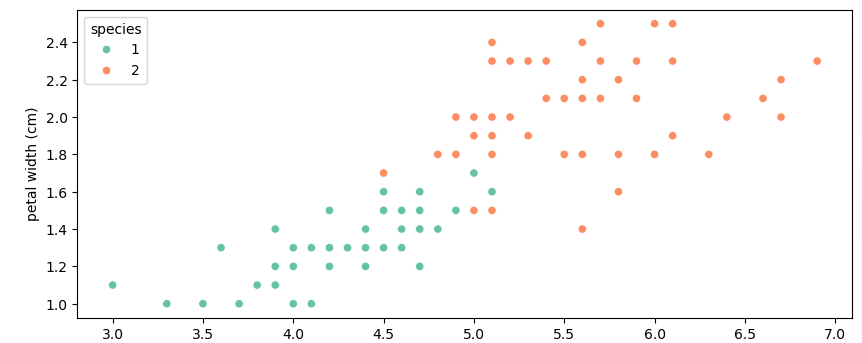
sns.scatterplot(x='petal length (cm)', y='petal width (cm)', data=iris_12, hue='species', palette='Set2');DataFrame을 만들고 해당 데이터에서 어떻게 분포 되어 있는지 확인 해보기 위해 scatterplot을 이용하여 출력해본 결과
중간에서 몇개의 길이와 너비가 조금씩 겹치는 것이 확인 되었습니다.
이제 본격적으로 ML을 활용하여 해당 특성들을 이용하여 구별해보겠습니다.
(저희는 Tree 알고리즘을 이용해 모델을 만들겠습니다.)
from sklearn.tree import DecisionTreeClassifier
iris_tree = DecisionTreeClassifier() # 모델
iris_tree.fit(iris.data[:, 2:], iris.target)우선 DecisionTreeClassifier()를 통해 모델을 불러왔습니다.
iris[:, 2:]을 이용한 이유
data[행, 열] 이므로 data[모든 행, 2 ~ 3열]을 하여 petal_width와 petal_length의 특성만 가져오기 위해서 이렇게 사용하였습니다.
fit을 사용할 때는 첫 번째로 data의 특성과 Label(정답)을 줘야 하기 떄문에 iris.target을 이용하였습니다.
이렇게 완료를 하게 되면 iris_tree에 모델을 통해 학습이 되게 됩니다.
import matplotlib.pyplot as plt
from sklearn import tree
fig = plt.figure(figsize=(10,10))
_ = tree.plot_tree(iris_tree, feature_names=['length', 'width'],
class_names=list(iris.target_names), filled=True
)
# depth 즉, 트리의 높이가 5로 매우 큰 것으로 보인다.
일단 맨위의 박스를 해석해보면 petal_width 가 0.8보다 작거나 같다면 해당 클래스는 setosa로 설정하고 아래로 내려가서 왼쪽을 보면(즉, 위의 박스에 대한 조건이 참일 경우) 주황색 박스에서 또 다른 기준으로 구별하는 박스가 없는 것으로 보아선 petal_width가 0.8이하면 setosa로 결정되는 것으로 보입니다.
이제 오른쪽을 보면( 즉, 위의 박스에 대한 조건이 거짓일 경우) 아래로 여러개의 박스들이 쭉쭉 뻗어나가는 것을 보실 수 있습니다. 수 많은 박스들이 versicolor와 virginica를 구별하기 위한 조건들입니다.
이제 어떻게 구분 되었는지 확인해보겠습니다.
from mlxtend.plotting import plot_decision_regions
plt.figure(figsize=(10, 6))
plot_decision_regions(X=iris.data[:, 2:], y=iris.target,
clf=iris_tree, # 학습을 완료한 모델 넣는 곳
legend = 2
);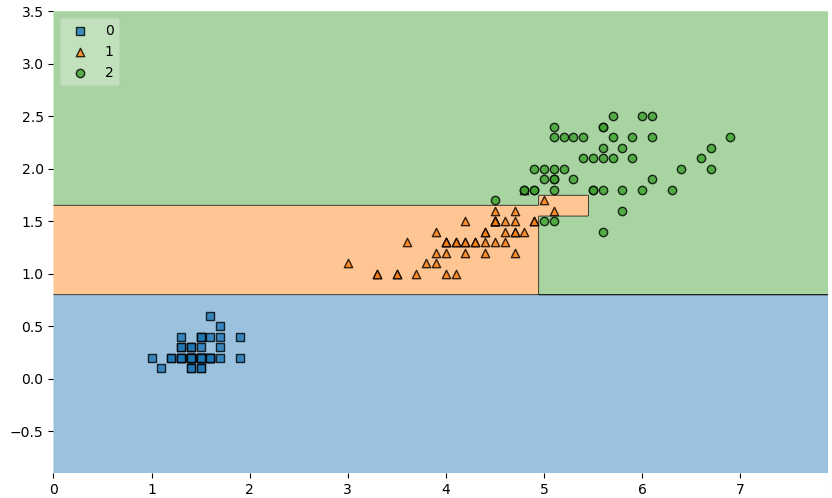
위의 그림을 보면 1번 과 2번의 품종을 나누기 위해 조그맣게 또 나뉜 것을 보실 수 있습니다.
이제 이렇게 보기에는 정말 정확하게 나눈 것으로 볼 수 있으나, 문제가 있습니다.
만약 중간에 섞여있는 데이터 2개가 1번 데이터이지만 크기가 돌연변이에 의해 2번 데이터 크기로 나오는 경우 나중에 해당 돌연변이 데이터 있는 구간의 크기의 2번 데이터를 넣었을 때 모든 결과가 1번으로 나올 수 있습니다.
그리고 저희의 데이터는 고작 150개로 매우 적은 데이터의 양을 가지고 하는 것이기 때문에 해당 모델이 정확하다 말할 수 없고 과적합 되었다고 말할 수 있습니다.
과적합(overfit) : 내가 준 데이터에 너무 최적화 된 것. 즉, 모델의 데이터가 내 데이터에만 최적화 된 것.
이를 해결할 방법은 데이터의 분리 하여 나의 모델이 훈련용 데이터에 너무 과적합되지 않고 일반성을 확보하는 것입니다.
from sklearn.model_selection import train_test_split # 데이터 나누는 라이브러리
features = iris.data[:, 2:]
labels = iris.target
X_train, X_test, y_train, y_test = train_test_split(
features,
labels,
test_size=0.2, # 8:2로 train과 테스트 데이터를 나눈다.
stratify=labels, # 0, 1, 2 라벨을 기준으로 똑같은 개수로 나눠준다. 즉, 30개의 test 데이터를 10, 10, 10으로 나눈다.
random_state=13
) # 4개의 값으로 나눈다. X_train: 특성 데이터 X_test: 테스트할 특성 데이터위의 코드 내용처럼 train_test_split을 활용하여 데이터 셋의 일부를 떼어내어 테스트할 때 사용하도록 데이터를 분리하였습니다.
이제는 tree모델을 사용할 때 돌연변이나 변수들이 많으니, 너무 깊숙하게 기준을 걸지 말고 트리의 높이를 2로 줄이겠습니다.
iris_tree = DecisionTreeClassifier(max_depth=2, random_state=13) # 두번만 나눠라
iris_tree.fit(X_train, y_train)
fig = plt.figure(figsize=(10,8))
_ = tree.plot_tree(iris_tree, feature_names=['length', 'width'],
class_names=list(iris.target_names), filled=True)
# depth 즉 트리의 높이가 2로 바뀐 것을 확인 할 수 있다.
위의 사진 처럼 트리의 높이가 2가 된 것을 확인 하실 수 있습니다.
이번에는 데이터가 위의 기준을 통해 어떻게 나뉘었는지 확인해보겠습니다.
plt.figure(figsize=(10,6))
plot_decision_regions(X=X_train, y=y_train, clf=iris_tree)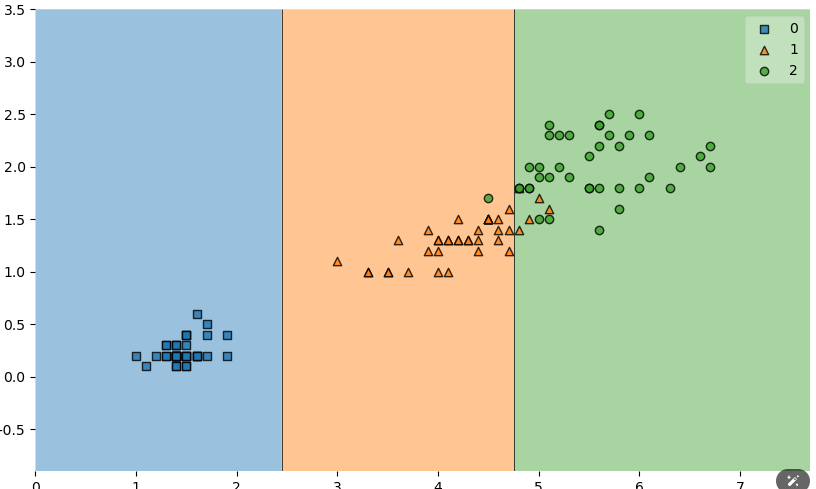
처음과는 달리 매우 간단하게 나뉜 것을 확인 할 수 있습니다.
이번에는 훈련이 잘 되었는지 정확도 체크를 해보겠습니다.
from sklearn.metrics import accuracy_score
# 훈련 데이터로 측정
y_pred_tr = iris_tree.predict(X_train) # X_train 예측한 결과
accuracy_score(y_train, y_pred_tr) # 정확도
# 테스트 데이터로 측정 -> 훈련 데이터셋에 없던 특성들을 통해 구별
y_pred_test = iris_tree.predict(X_test)
accuracy_score(y_test, y_pred_test)해당 코드를 해보니 훈련데이터로 예측한 정확도는 0.95가 나온 것을 확인 하였습니다.
테스트 데이터로는 0.96이 나온 것을 확인 하였습니다.
그래도 이제 정확도도 꽤 높은 것으로 확인 되었으니 아무 데이터를 넣어서 테스트를 해보겠습니다.
test_data = [[4.3, 2., 1.2, 1.0]] # 그냥 임의의 데이터 해보고픈 숫자
iris_tree.predict(test_data)해당 내용을 넣어 실험해본 결과 1번이 확인 되었습니다. 즉 해당 특성의 품종은 'versicolor'인 것으로 확인 되었습니다.
이제 마지막으로 맨 위에서 어떤 특성이 품종을 분류하는데 영향을 주는지 boxplot을 통해 확인을 해보았었습니다.
이번에는 feature_importances_를 활용하여 확인 하는 방법을 보여드리겠습니다.
dict(zip(iris.feature_names, iris_tree.feature_importances_)){'sepal length (cm)': 0.0,
'sepal width (cm)': 0.0,
'petal length (cm)': 0.421897810218978,
'petal width (cm)': 0.578102189781022}해당 코드를 사용하면 위의 결과가 나옵니다. 해당 결과를 보아하니 저희가 boxplot을 이용해 확인했던 것처럼 petal length와 petal width가 영향있는 특성으로 측정되는 것을 확인 하실 수 있습니다.
이상으로 IRIS 품종 분류하는 코드를 마치겠습니다.
이 글은 제로베이스 데이터 분석 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.
'Data Analyst > ML' 카테고리의 다른 글
| [Zero-base]Linear Regression 2(보스턴 집 값 예측) (0) | 2024.09.30 |
|---|---|
| [Zero-base]Linear Regression (0) | 2024.09.30 |
| ML - Matplotlib SubPlots (1) | 2024.09.16 |
| ML - Matplotlib Figure Object (1) | 2024.09.10 |
| ML - Matplotlib-Basics (0) | 2024.09.10 |