Scaling
Label Encoder
- 글자를 만나면 숫자로 바꿔준다.
- 글자로 되어있는 특성(feature)들을 다 숫자로 바꿔야만 머신러닝 딥러닝이 잘 동작한다.
1. 우선 데이터를 만들어 줍니다.
import pandas as pd
df = pd.DataFrame({
'A' : ['a', 'b', 'c', 'a', 'b'],
'B' : [1, 2, 3, 1, 2]
})
2. LabelEncoder를 통해 'A' 컬럼 기준으로 학습 시켜보겠습니다.
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(df['A'])
3. 학습시킨 값들을 보니 array(['a', 'b', 'c'], dtype=object) 이렇게 a, b, c를 구별한 것을 확인 할 수 있었습니다.
4. DataFrame에 옮겨 학습시킨 결과를 확인하겠습니다.
df['le_A']=le.transform(df['A'])
df
A를 LabelEncoder로 모델링 해준 결과 신기하게도 a=0으로 b=1로 c=2로 구별 한 것을 확인 할 수 있습니다.
위에서 설명한 것과 같이 문자열을 정수형으로 변경해준 것을 볼 수 있습니다.
min-max scaling
- 0~1 사이의 값으로 정규화 해준다.
1. Data를 만들어줍니다.
df = pd.DataFrame({
'A' : [10, 20, -10, 0, 25],
'B' : [1, 2, 3, 1, 0]
})
df
2. MinMaxScaler를 통해 학습해줄 것입니다.
from sklearn.preprocessing import MinMaxScaler
mms = MinMaxScaler()
mms.fit(df)
mms.transform(df)해당 모델링을 통해 값을 transform을 사용하여 변경해줍니다.

모든 숫자들이 0과 1 사이의 값으로 변경된 것을 확인 할 수 있습니다. 코드결과에서 0과 1은 기존의 최솟값과 최댓값들 입니다.
standard scaling
- 표준편차, 평균의 값을 알아내야 한다.
- 데이터를 평균이 0, 분산이 1이 되도록 정규화하는 방법
1. 위에서 사용하였던 df를 사용하여 StandardScaler를 통해 학습 시키겠습니다. 그리고 학습된 결과를 출력하겠습니다.
from sklearn.preprocessing import StandardScaler
ss= StandardScaler()
ss.fit(df)
ss.transform(df)
보이는 것과 같이 숫자가 모두 바뀐 것을 확인할 수 있습니다.
2. 이번에는 해당 A컬럼의 값들의 평균이 0인지 표준편차가 1인지 확인해보겠습니다.
import numpy as np
a = ss.fit_transform(df)
np.mean(a[:, 0]), np.std(a[:, 0])확인 결과 0과 1로 나온 것을 확인 할 수 있었습니다. 이렇게 스케일링이 잘 된것입니다!
Robust Scaler
- Q1, Q2, Q3 값을 알아내야 한다.
- box plot에서 Q1, Q2, Q3만 보겠다는 방법이며
- Q2의 값을 0으로 바꾸고 Q3 - Q1으로 나누는 방법이다.
1. RobustScaler를 사용해 학습해보고 위에서 했던 모든 스케일링을 박스플롯으로 표현하겠습니다.
from sklearn.preprocessing import RobustScaler
from sklearn.preprocessing import MinMaxScaler, StandardScaler, RobustScaler
df = pd.DataFrame({
'A' : [-0.1, 0. , 0.1, 0.2, 0.3, 0.4, 1.0, 1.1, 5.]
})
mm = MinMaxScaler()
ss = StandardScaler()
rs = RobustScaler()
df_scaler = df.copy()
df_scaler['mm'] = mm.fit_transform(df)
df_scaler['ss'] = ss.fit_transform(df)
df_scaler['rs'] = rs.fit_transform(df)
df_scaler
확실히 원래의 값이 A 컬럼에 있던 값들이나, 모두 바뀐 것을 확인 할 수 있습니다.
2, 이제 해당 값들을 모두 박스 플롯으로 표현해보겠습니다.
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme(style='whitegrid')
plt.figure(figsize=(10,5))
sns.boxenplot(data = df_scaler, orient='h', palette='Set2')
# ss : 대다수의 데이터가 0 이하로 가서 학습시키는데 방해가 될수도 있다.
# rs : 원본과 가장 비슷하다. 그래서 현재로 보기에는 rs가 가장 좋은 스케일러가 될 수 있다 판단 할 수 있다.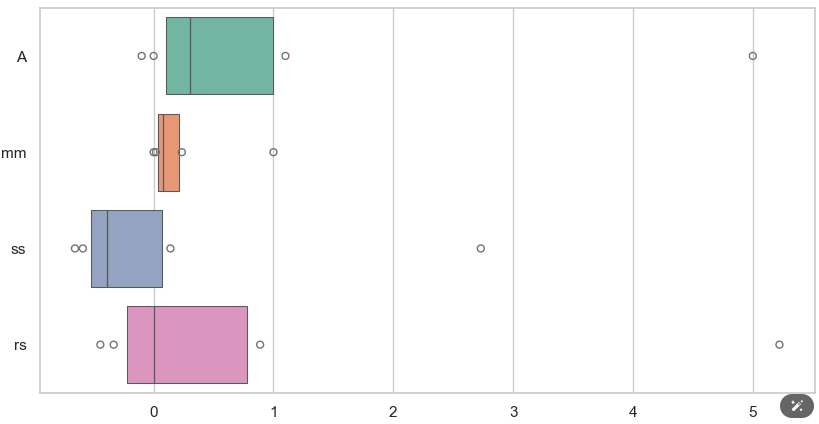
확실히 mm은 박스플롯이 많이 구겨진 것을 볼 수 있고 ss는 대다수의 데이터가 0이하로 가서 학습하는데 방해 될 것 같습니다.
이 중 rs의 박스플롯이 확실히 가장 원본가 흡사한 걸로 보아 이 중 제일 좋은 스케일러 인 것 같습니다.
이 것으로 Scaler 내용을 마치겠습니다.
Scaler는 어느 때 좋은 거라는 생각은 버리고 데이터 분석이나 전처리를 할 때 위의 모든 방법을 해보고 그 중 가장 좋은 스케일링 방법을 사용해야 합니다.
분류 모델 평가
Accuracy(정확도) : 전체 데이터에서 맞힌 비율입니다.
Precision(정밀도) : 양성이라고 예측한 것에서 맞힌 비율입니다.
Recall(재현율) : 참인 데이터들 중에서 참이라고 예측한 비율입니다.(TPR(True Positvie Rate))
Fall-Out( = FPR(False Positive Rate)) : 실제 양성이 아닌데 양성이라 잘못 예측한 경우 입니다.
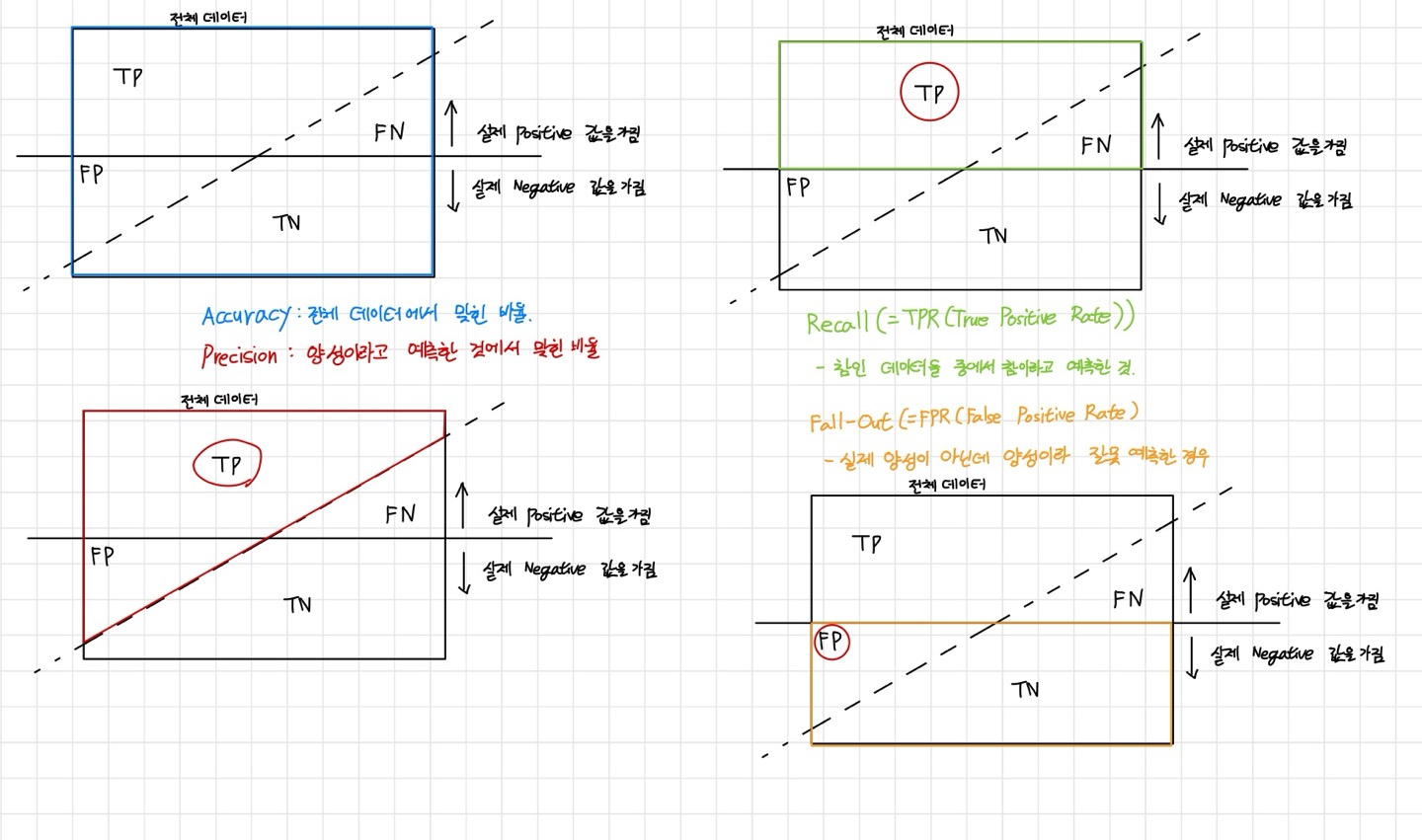
해당 분류 모델 평가하는 값들 또한 모두 sklearn에 있습니다.
1. 전에 사용했던 Tree모델로 구별한 Wine 데이터를 활용하여 평가 해보겠습니다.
from sklearn.metrics import accuracy_score, precision_score, recall_score
from sklearn.metrics import recall_score, f1_score, roc_auc_score, roc_curve
print("accuracy_score", accuracy_score(y_test, y_pred_test))
print("recall_score", recall_score(y_test, y_pred_test))
print("precision_score", precision_score(y_test, y_pred_test))
print("roc_auc_score", roc_auc_score(y_test, y_pred_test))
print("f1_score", f1_score(y_test, y_pred_test))
보이는 것과 같이 분류 모델 평가하는 값들이 나온 것을 확인할 수 있습니다.
제가 보기에는 살짝 낮긴 하지만 그래도 어느정도 잘 맞춘 것 같습니다. 그러므로 모델의 성능은 그럭저럭인 것 같습니다.
True Positive? False Positive?
False Positve(FPR)과 True Positive(TPR) 은 ROC Curve에서 각각 x, y축에 표시합니다.
예를 들어 암 검사를 받기 위해 내원했다 가정하겠습니다.
Positive : 의사가 암에 걸렸다(Positive)고 판단.
해당 가정들을 토대로 True와 False에 의미 : '판단을 올바르게 했다', '판단을 틀리게 했다'라는 뜻입니다.
True Positive : 실제로 암에 걸린 사람을 암환자로 판단.
False Positive : 암환자가 아닌데 암에 걸렸다고 오진.
Threshold(임계값) : 머신러닝의 결과로 label에 대한 확률을 반환할 떄 이 확률이 몇 이상일 때 그 Label 이라고 볼 것인가에 대한 설정값입니다.

이번에는 위의 그림과 예시를 들고 설명하겠습니다.
의사A : 모든 환자를 암환자로 판단합니다. 즉 Threshold가 매우 낮습니다.
- 실제로 암에 걸린 사람들은 모두 암환자로 판정 => True Positive Rate 가 높아집니다.
- 암에 걸리지 않은 사람들도 암환자로 판정 => False Positive Rate가 높아집니다.
의사B : 모든 환자를 정상으로 판단합니다. 즉 Threshold가 매우 높습니다.
- 실제로 암에 걸린 사람들은 모두 정상을 판정 => True Positive Rate가 낮아집니다.
- 암에 걸리지 않은 사람들을 정상으로 판정 => False Positive Rate가 낮아집니다.
ROC Curve에서 현 위의 점의 의미는? 현의 휨 정도가 의미하는 것은?
현 위의 점의 의미는 모든 가능한 threshold에 대해 FPR과 TPR을 알아보겠다는 의미입니다.
현의 휨의 정도가 의미하는 것은 두 클래스를 더 잘 구별 할 수 있는 것을 의미합니다.
해당 설명은 그림을 봐주시면 되겠습니다.

해당 Roc Curve를 보는 방법들은 모두 설명하였으니 Python을 통해 구현해보겠습니다.
1. roc_curve를 사용하여 fpr과 tpr, threshold를 가져오겠습니다.
import matplotlib.pyplot as plt
pred_proba = wine_tree.predict_proba(X_test)[:, 1] # proba를 통해 어느정도 확률로 선택했는지 확인
fpr, tpr, threshold = roc_curve(y_test, pred_proba)
fpr, tpr ,threshold
위에서 말한 것처럼 해당 내용은 threshold(3번째에 있는 값)에 따라 fpr과 tpr이 어느정도의 값을 가지고 있는지 보여주는 것입니다.
2. 이제 그래프를 직접 시각화 해보겠습니다.
plt.figure(figsize=(10, 8))
plt.plot([0,1], [0,1], 'r')
plt.plot(fpr, tpr)
plt.grid()
plt.show()
보이는 것과 같이 ROC Curve를 만들었습니다.
네 이상으로 분류모델 평가를 마치겠습니다.
이 글은 제로베이스 데이터 분석 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.
수학관련 내용은 해당 유튜브에서 참고하였습니다.
'Data Analyst > ML' 카테고리의 다른 글
| [Zero-base] Logistic Regression - 1 (1) | 2024.10.03 |
|---|---|
| [Zero-base] Pipeline (0) | 2024.10.03 |
| [Zero-base] Linear Regression(Wine 구별, Scaler) (0) | 2024.10.01 |
| [Zero-base]Linear Regression 2(보스턴 집 값 예측) (0) | 2024.09.30 |
| [Zero-base]Linear Regression (0) | 2024.09.30 |