HAR 데이터 소개
UCI HAR 데이터 셋은 스마트폰을 장착한 사람의 행동을 관찰한 데이터입니다.
- 실험 대상 : 19-48세 연령의 30명의 자원 봉사자를 모집하여 수행
- 허리에 스마트 폰을 착용하여 50Hz의 주파수로 데이터를 얻습니다.
- 6가지 활동을 수행합니다.
- 실험은 데이터를 수동으로 라벨링하기 위해 비디오로 기록합니다.
- 시간 영역 데이터를 머신러닝에 적용하기 위해 여러 통계적 데이터로 변환합니다.
- 시간 영역의 평균, 분산, 피크, 중간 값, 주파수 영역에 평균, 분산 등으로 변환한 수치를 가지고 있습니다.
- 이걸 데이터화 시키는 것을 Feature Extraction(특징 추출)이라 합니다.
- 이를 통해 사람이 앉았는지, 걷는지, 계단을 내려가는지, 올라가는지, 그냥 서있는지를 알 수 있게 만들었습니다.
데이터 특성
- 가속도계로부터의 3 축 가속도 (총 가속도) 및 추정 된 신체 가속도
- 자이로 스코프의 3축 각속도
- 시간 및 주파수 영역 변수가 포함 된 561 기능 벡터
- 활동 라벨
- 실험을 수행 한 대상의 식별자
머신러닝을 이용한 행동인식 순서
- 센서신호(Raw sensor signal)
- 특징 추출(Feature extraction)
- 모델 학습(Model training)
- 행동 추론(Activity inference)
결론은 휴대폰을 가지고 있을 때 해당 휴대폰에 수집되는 데이터를 통해 내 행동을 알아내는 실험을 한 것이다.
1. HAR 컬럼(Feature)를 불러오겠습니다.
import pandas as pd
import matplotlib.pyplot as plt
# DATA를 읽은 것이 아닌 이것은 컬럼을 읽어온 것이다. 즉 컬럼들이다.
url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/refs/heads/master/dataset/HAR_dataset/features.txt'
feature_name_df = pd.read_csv(url, sep='\s+', header=None, names=['column_index', 'column_name'])
# 컬럼들의 개수가 561개로 매우 많다.
len(feature_name_df)확인해보니 컬럼들의 개수가 무려 561개로 매우 많은 것을 확인하였습니다.
2. train세트, test 세트를 불러오겠습니다.
X_train_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/refs/heads/master/dataset/HAR_dataset/train/X_train.txt'
X_test_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/refs/heads/master/dataset/HAR_dataset/test/X_test.txt'
X_train = pd.read_csv(X_train_url, sep='\s+', header=None)
X_test = pd.read_csv(X_test_url, sep='\s+', header=None)
y_test_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/refs/heads/master/dataset/HAR_dataset/test/y_test.txt'
y_train_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/refs/heads/master/dataset/HAR_dataset/train/y_train.txt'
y_train = pd.read_csv(y_train_url, sep='\s+', header=None, names=['action'])
y_test = pd.read_csv(y_test_url, sep='\s+', header=None, names=['action'])
X_train.shape, X_test.shape, y_train.shape, y_test.shape훈련 세트와 테스트 세트 불러오고 shape을 확인한 결과 ((7352, 561), (2947, 561), (7352, 1), (2947, 1)) 훈련세트와 테스트 세트는 비율이 맞게 입력되어 있는 것 같습니다.
3. Label 확인해보겠습니다.
# 각 액션별 데이터 수
y_train['action'].value_counts()
# 라벨마다 균형이 맞는 것은 또 아님.라벨마다 균형이 맞는 것이 아닌 것이 확인됩니다.

4. LabelEncoder를 사용하여 Label값들을 숫자 형태로 변환
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y_train = le.fit_transform(y_train.to_numpy().ravel())
y_test = le.fit_transform(y_test.to_numpy().ravel())LabelEncoder()를 통해 숫자 형태로 변환해주며내서 ravel()을 통해 1차원으로 평탄화 작업까지 해줍니다. 왜냐하면 데이터를 모델이 다루기 쉬운 형태로 바꾸기 위함입니다.
5. 결정 나무 알고리즘으로 모델링하고 정확도 평가해보겠습니다.
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
df_clf = DecisionTreeClassifier(random_state=13, max_depth=4)
df_clf.fit(X_train, y_train)
pred = df_clf.predict(X_test)
accuracy_score(y_test, pred)결정 나무로 모델링을 하여 정확도를 확인 해본 결과 81%가 나왔습니다.
6. GridSearchCV를 통해 하이퍼파라미터를 튜닝하는 동시에 5개의 폴드로 데이터세트를 나눠 테스트를 해보겠습니다.
from sklearn.model_selection import GridSearchCV
params = {
'max_depth' : [6, 8, 10, 12, 16, 20, 24]
}
# cv -> 데이터를 n개의 폴드로 나누어 그 중 하나는 테스트 데이터, 나머지 n-1개는 학습 데이터로 사용합니다.
# 이 과정을 n번 반복하여 각각 다른 폴드를 테스트 데이터로 사용합니다.
grid_cv = GridSearchCV(df_clf, param_grid=params, scoring='accuracy', cv=5, return_train_score=True)
grid_cv.fit(X_train, y_train)
# 정확도가 제일 좋은 값
grid_cv.best_score_
# 제일 좋은 max_depth 확인
grid_cv.best_params_해당 코드 결과 이전의 결정 나무를 통해 만든 모델 보다 5개의 폴드로 나눠서 정확도를 평가하고 평균 값을 확인 해본 결과 85%로 확인되었으며, 하이퍼파라미터인 max_depth가 8인 모델이 가장 좋은 것으로 확인 되었습니다.
7. fold로 나누지 않고 max_depth를 8로 설정하고 정확도 평가하기
df_clf = DecisionTreeClassifier(max_depth=8, random_state=13)
df_clf.fit(X_train, y_train)
pred = df_clf.predict(X_test)
accuracy = accuracy_score(y_test, pred)
print('Max_depth = ', depth, ', Accuracy =', accuracy)코드 결과 87%로 처음 결과보다 매우 올라간 것을 확인 할 수 있었습니다.
8. RandomForest 알고리즘을 사용하면서 최적의 하이퍼파라미터도 찾아보겠습니다.
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
params = {
'max_depth' : [6, 8, 10],
'n_estimators' : [50, 100, 200] # 모델에서 사용하는 트리의 개수를 의미합니다. 즉, 앙상블 모델이 학습할 때 몇 개의 의사결정 나무(Decision Trees)를 만들지 결정하는 하이퍼파라미터입니다.
}
rf_clf = RandomForestClassifier(random_state=13, n_jobs=-1)
grid_cv = GridSearchCV(rf_clf, param_grid=params, cv=2, n_jobs=-1)
grid_cv.fit(X_train, y_train)
target_col = ['rank_test_score', 'mean_test_score', 'param_n_estimators', 'param_max_depth']
cv_results_df[target_col].sort_values('rank_test_score').head()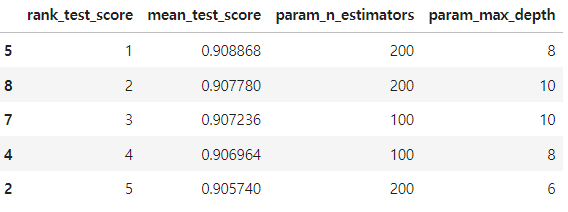
코드 확인 결과 max_depth = 8, n_estimators = 200으로 사용했을 경우가 제일 정확한 값이 나오는 것을 확인 할 수 있습니다.
심지어 정확도 평균이 90%인 것을 확인 할 수 있었습니다.
그리고 폴드를 사용하지 않고 정확도를 확인 해본결과 91%로 매우 많이 올라간 것을 확인 할 수 있었습니다.
9. 컬럼들이 끼치는 영향을 확인 해보겠습니다.
best_cols_values = rf_clf_best.feature_importances_
best_cols = pd.Series(best_cols_values, index=X_train.columns)
top20_cols = best_cols.sort_values(ascending=False)[:100] # 중요 특성 20개 출력
top20_cols
# 각 특성들의 중요도가 개별적으로 높지 않다...
특성 마다 영향도를 확인 해보았는데 각 컬럼마다 매우 낮은 것을 확인 할 수 있었습니다. 즉, 쓸모 없는 컬럼들이 많은 것을 알 수 있는 것 같습니다.
그럼 모든 컬럼을 사용해서 모델링을 할 필요가 없는 것 같습니다.
10. 중요 특성 20개로만 사용하여 정확도 평가하기
# 563개가 있던 컬럼을 중요한 특성 20개로 줄여서 다시 데이터를 구성
# 성능은 조금 포기하더라도 20개의 특성만 본다면 연산 속도가 매우 빨라질 것이다. -> 이렇게 할수도 있는 것이지 꼭 이방법을 사용하는 것은 아니다.
X_train_re = X_train[top20_cols.index]
X_test_re = X_test[top20_cols.index]
rf_clf_best_re = grid_cv.best_estimator_ # 제일 성능이 좋았던 모델 사용
rf_clf_best_re.fit(X_train_re, y_train) # 컬럼이 20개인 값만 사용해서 해보겠다
pred1_re = rf_clf_best_re.predict(X_test_re)
accuracy_score(y_test, pred1_re)
# 가장 중요한 특성 5개만 가져왔더니 62%의 정확도를 가진다. 이말은 즉, 561개의 컬럼의 영향이 한 개당 1%도 안되는데 그 컬럼들을 쓸 것인가 라는 생각을 가질 수 있다.
# 100개를 가져오니 성능이 매우 올라간 것을 확인할 수 있다.이렇게 중요한 20개 특성을 가져와서 모델 전에 나왔던 정확도 보다 내려간 89%의 정확도는 나왔으나, 연산 속도는 매우 빨라졌습니다.
이상으로 앙상블 기법 글을 마치겠습니다.
이 글은 제로베이스 데이터 분석 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.
'Data Analyst > ML' 카테고리의 다른 글
| [Zero-base] 주성분 분석(PCA, Principal Component Analysis) - 2 (3) | 2024.10.10 |
|---|---|
| [Zero-base] 주성분 분석(PCA, Principal Component Analysis) - 1 (0) | 2024.10.10 |
| [Zero-base] 앙상블 기법 - 1 (3) | 2024.10.08 |
| [Zero-base] KNN(KNeighbors Classifier) - 2 (0) | 2024.10.07 |
| [Zero-base] KNN(KNeighbors Classifier) - 1 (0) | 2024.10.07 |
HAR 데이터 소개
UCI HAR 데이터 셋은 스마트폰을 장착한 사람의 행동을 관찰한 데이터입니다.
- 실험 대상 : 19-48세 연령의 30명의 자원 봉사자를 모집하여 수행
- 허리에 스마트 폰을 착용하여 50Hz의 주파수로 데이터를 얻습니다.
- 6가지 활동을 수행합니다.
- 실험은 데이터를 수동으로 라벨링하기 위해 비디오로 기록합니다.
- 시간 영역 데이터를 머신러닝에 적용하기 위해 여러 통계적 데이터로 변환합니다.
- 시간 영역의 평균, 분산, 피크, 중간 값, 주파수 영역에 평균, 분산 등으로 변환한 수치를 가지고 있습니다.
- 이걸 데이터화 시키는 것을 Feature Extraction(특징 추출)이라 합니다.
- 이를 통해 사람이 앉았는지, 걷는지, 계단을 내려가는지, 올라가는지, 그냥 서있는지를 알 수 있게 만들었습니다.
데이터 특성
- 가속도계로부터의 3 축 가속도 (총 가속도) 및 추정 된 신체 가속도
- 자이로 스코프의 3축 각속도
- 시간 및 주파수 영역 변수가 포함 된 561 기능 벡터
- 활동 라벨
- 실험을 수행 한 대상의 식별자
머신러닝을 이용한 행동인식 순서
- 센서신호(Raw sensor signal)
- 특징 추출(Feature extraction)
- 모델 학습(Model training)
- 행동 추론(Activity inference)
결론은 휴대폰을 가지고 있을 때 해당 휴대폰에 수집되는 데이터를 통해 내 행동을 알아내는 실험을 한 것이다.
1. HAR 컬럼(Feature)를 불러오겠습니다.
import pandas as pd
import matplotlib.pyplot as plt
# DATA를 읽은 것이 아닌 이것은 컬럼을 읽어온 것이다. 즉 컬럼들이다.
url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/refs/heads/master/dataset/HAR_dataset/features.txt'
feature_name_df = pd.read_csv(url, sep='\s+', header=None, names=['column_index', 'column_name'])
# 컬럼들의 개수가 561개로 매우 많다.
len(feature_name_df)확인해보니 컬럼들의 개수가 무려 561개로 매우 많은 것을 확인하였습니다.
2. train세트, test 세트를 불러오겠습니다.
X_train_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/refs/heads/master/dataset/HAR_dataset/train/X_train.txt'
X_test_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/refs/heads/master/dataset/HAR_dataset/test/X_test.txt'
X_train = pd.read_csv(X_train_url, sep='\s+', header=None)
X_test = pd.read_csv(X_test_url, sep='\s+', header=None)
y_test_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/refs/heads/master/dataset/HAR_dataset/test/y_test.txt'
y_train_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/refs/heads/master/dataset/HAR_dataset/train/y_train.txt'
y_train = pd.read_csv(y_train_url, sep='\s+', header=None, names=['action'])
y_test = pd.read_csv(y_test_url, sep='\s+', header=None, names=['action'])
X_train.shape, X_test.shape, y_train.shape, y_test.shape훈련 세트와 테스트 세트 불러오고 shape을 확인한 결과 ((7352, 561), (2947, 561), (7352, 1), (2947, 1)) 훈련세트와 테스트 세트는 비율이 맞게 입력되어 있는 것 같습니다.
3. Label 확인해보겠습니다.
# 각 액션별 데이터 수
y_train['action'].value_counts()
# 라벨마다 균형이 맞는 것은 또 아님.라벨마다 균형이 맞는 것이 아닌 것이 확인됩니다.
4. LabelEncoder를 사용하여 Label값들을 숫자 형태로 변환
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y_train = le.fit_transform(y_train.to_numpy().ravel())
y_test = le.fit_transform(y_test.to_numpy().ravel())LabelEncoder()를 통해 숫자 형태로 변환해주며내서 ravel()을 통해 1차원으로 평탄화 작업까지 해줍니다. 왜냐하면 데이터를 모델이 다루기 쉬운 형태로 바꾸기 위함입니다.
5. 결정 나무 알고리즘으로 모델링하고 정확도 평가해보겠습니다.
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
df_clf = DecisionTreeClassifier(random_state=13, max_depth=4)
df_clf.fit(X_train, y_train)
pred = df_clf.predict(X_test)
accuracy_score(y_test, pred)결정 나무로 모델링을 하여 정확도를 확인 해본 결과 81%가 나왔습니다.
6. GridSearchCV를 통해 하이퍼파라미터를 튜닝하는 동시에 5개의 폴드로 데이터세트를 나눠 테스트를 해보겠습니다.
from sklearn.model_selection import GridSearchCV
params = {
'max_depth' : [6, 8, 10, 12, 16, 20, 24]
}
# cv -> 데이터를 n개의 폴드로 나누어 그 중 하나는 테스트 데이터, 나머지 n-1개는 학습 데이터로 사용합니다.
# 이 과정을 n번 반복하여 각각 다른 폴드를 테스트 데이터로 사용합니다.
grid_cv = GridSearchCV(df_clf, param_grid=params, scoring='accuracy', cv=5, return_train_score=True)
grid_cv.fit(X_train, y_train)
# 정확도가 제일 좋은 값
grid_cv.best_score_
# 제일 좋은 max_depth 확인
grid_cv.best_params_해당 코드 결과 이전의 결정 나무를 통해 만든 모델 보다 5개의 폴드로 나눠서 정확도를 평가하고 평균 값을 확인 해본 결과 85%로 확인되었으며, 하이퍼파라미터인 max_depth가 8인 모델이 가장 좋은 것으로 확인 되었습니다.
7. fold로 나누지 않고 max_depth를 8로 설정하고 정확도 평가하기
df_clf = DecisionTreeClassifier(max_depth=8, random_state=13)
df_clf.fit(X_train, y_train)
pred = df_clf.predict(X_test)
accuracy = accuracy_score(y_test, pred)
print('Max_depth = ', depth, ', Accuracy =', accuracy)코드 결과 87%로 처음 결과보다 매우 올라간 것을 확인 할 수 있었습니다.
8. RandomForest 알고리즘을 사용하면서 최적의 하이퍼파라미터도 찾아보겠습니다.
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
params = {
'max_depth' : [6, 8, 10],
'n_estimators' : [50, 100, 200] # 모델에서 사용하는 트리의 개수를 의미합니다. 즉, 앙상블 모델이 학습할 때 몇 개의 의사결정 나무(Decision Trees)를 만들지 결정하는 하이퍼파라미터입니다.
}
rf_clf = RandomForestClassifier(random_state=13, n_jobs=-1)
grid_cv = GridSearchCV(rf_clf, param_grid=params, cv=2, n_jobs=-1)
grid_cv.fit(X_train, y_train)
target_col = ['rank_test_score', 'mean_test_score', 'param_n_estimators', 'param_max_depth']
cv_results_df[target_col].sort_values('rank_test_score').head()코드 확인 결과 max_depth = 8, n_estimators = 200으로 사용했을 경우가 제일 정확한 값이 나오는 것을 확인 할 수 있습니다.
심지어 정확도 평균이 90%인 것을 확인 할 수 있었습니다.
그리고 폴드를 사용하지 않고 정확도를 확인 해본결과 91%로 매우 많이 올라간 것을 확인 할 수 있었습니다.
9. 컬럼들이 끼치는 영향을 확인 해보겠습니다.
best_cols_values = rf_clf_best.feature_importances_
best_cols = pd.Series(best_cols_values, index=X_train.columns)
top20_cols = best_cols.sort_values(ascending=False)[:100] # 중요 특성 20개 출력
top20_cols
# 각 특성들의 중요도가 개별적으로 높지 않다...특성 마다 영향도를 확인 해보았는데 각 컬럼마다 매우 낮은 것을 확인 할 수 있었습니다. 즉, 쓸모 없는 컬럼들이 많은 것을 알 수 있는 것 같습니다.
그럼 모든 컬럼을 사용해서 모델링을 할 필요가 없는 것 같습니다.
10. 중요 특성 20개로만 사용하여 정확도 평가하기
# 563개가 있던 컬럼을 중요한 특성 20개로 줄여서 다시 데이터를 구성
# 성능은 조금 포기하더라도 20개의 특성만 본다면 연산 속도가 매우 빨라질 것이다. -> 이렇게 할수도 있는 것이지 꼭 이방법을 사용하는 것은 아니다.
X_train_re = X_train[top20_cols.index]
X_test_re = X_test[top20_cols.index]
rf_clf_best_re = grid_cv.best_estimator_ # 제일 성능이 좋았던 모델 사용
rf_clf_best_re.fit(X_train_re, y_train) # 컬럼이 20개인 값만 사용해서 해보겠다
pred1_re = rf_clf_best_re.predict(X_test_re)
accuracy_score(y_test, pred1_re)
# 가장 중요한 특성 5개만 가져왔더니 62%의 정확도를 가진다. 이말은 즉, 561개의 컬럼의 영향이 한 개당 1%도 안되는데 그 컬럼들을 쓸 것인가 라는 생각을 가질 수 있다.
# 100개를 가져오니 성능이 매우 올라간 것을 확인할 수 있다.이렇게 중요한 20개 특성을 가져와서 모델 전에 나왔던 정확도 보다 내려간 89%의 정확도는 나왔으나, 연산 속도는 매우 빨라졌습니다.
이상으로 앙상블 기법 글을 마치겠습니다.
이 글은 제로베이스 데이터 분석 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.
'Data Analyst > ML' 카테고리의 다른 글
| [Zero-base] 주성분 분석(PCA, Principal Component Analysis) - 2 (3) | 2024.10.10 |
|---|---|
| [Zero-base] 주성분 분석(PCA, Principal Component Analysis) - 1 (0) | 2024.10.10 |
| [Zero-base] 앙상블 기법 - 1 (3) | 2024.10.08 |
| [Zero-base] KNN(KNeighbors Classifier) - 2 (0) | 2024.10.07 |
| [Zero-base] KNN(KNeighbors Classifier) - 1 (0) | 2024.10.07 |