Data Frame - 2
Data Frame 인덱스 선택하기
- column들을 기반으로 선택하는 방법입니다.
- 딕셔너리에서 키값을 넣으면 값이 나오는 방법 처럼 해당 컬럼명을 넣으면 해당 컬럼의 값들이 출력 됩니다.
df['total_bill']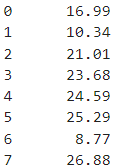
- 그리고 위의 코드 결과의 타입은 Series 타입입니다.
- 이번에는 두 개의 컬럼을 가져오겠습니다.
# 여기서 중요한 점은 두 개의 컬럼을 가져오는 경우 이중 대괄호를 사용해야 한다.
df[['total_bill','tip']]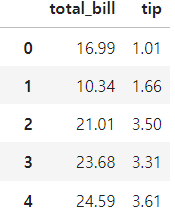
- 여기서 위의 코드에서도 말했듯이 두 개 이상의 컬럼을 사용하는 경우에는 이중 대괄호를 사용해야 합니다.
- 이유 : 이중 대괄호를 사용한다는 것은 타입이 DataFrame 값을 출력하는 것입니다.
또 한 가지를 저희는 기억해야 합니다. Series는 1차원 배열이고, DataFrame은 2차원 구조를 가지게 되어있습니다.
즉, 컬럼을 두 개이상 사용한다는 것은 2차원 배열을 사용해야 한다는 것이고 이 말은 DataFrame으로 출력해야 한다는 것입니다.
Data Frame에 새로운 Column값 만들기
- Data Frame에 컬럼을 추가하는 방법은 매우 간단합니다.
# tip_percentage라는 컬럼을 추가하고 값으로는 tip값의 퍼센티지를 넣어주는 코드입니다.
df['tip_percentage'] = 100* df['tip'] / df['total_bill']
df.head()
- 맨 뒤에 'tip_percentage'가 추가 된 것을 확인 할 수 있습니다.
Data Frame에 Column 지우기
- Data Frame에 존재하는 컬럼을 제거 하는 방법은 drop을 사용하면 됩니다.
# axis = 0 -> 행
# axis = 1 -> 열
df = df.drop("tip_percentage",axis=1)
df.head()
- 맨 뒤의 'tip_percentage'가 삭제 된 것을 확인 할 수 있습니다.
Data Frame에 Index 설정하기
- Data Frame에 인덱스를 설정 하는 방법은 set_index()함수를 사용하면 됩니다.
# Payment ID로 인덱스를 설정
df.set_index('Payment ID')- 'Payment ID'를 기준으로 DataFrame이 바뀌게 됩니다.
- 아래의 코드 결과를 보면 바뀐게 없어 보이지만 해당 인덱스를 기준으로 이제 값이 출력되는 것으로 보일 것입니다.

- reset_index()를 사용하게 되면 설정된 인덱스가 없어지게 됩니다.
Data Frame Rows
- Row값을 조회할 때는 숫자형으로 조회할 때와 문자열로 조회할 때는 서로 다른 함수를 사용합니다.
# Integer Based
df.iloc[0]
# Name Based
df.loc['Sun2959']
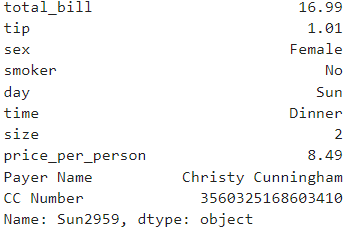
- 위의 결과와 같이 해당 인덱스의 데이터의 정보가 출력 됩니다.(1차원 배열이기 때문에 Series 타입!!)
- 여러 Row를 조회 하고 싶을 떄는 인덱스 슬라이싱을 사용해주면 됩니다.
# 인덱스 슬라이싱 사용하여 0~4의 인덱스의 모든 데이터 값을 가져옴
df.iloc[0:4]
# 인덱스 슬라이싱이 아닌 이중 대괄호를 사용하여 name값을 넣어 조회 할수도 있음.
df.loc[['Sun2959','Sun5260']]Data Frame Rows 삭제
- column 삭제와 같이 Row 삭제할 때도 drop을 사용하면 됩니다.
# axis = 0 -> 행
# head()를 통해 삭제된 것을 확인.
df.drop('Sun2959',axis=0).head()
# 만약에 name을 넣지 않고 숫자형을 넣게되면 오류가 발생한다!!
# df.drop(0,axis=0).head()Data Frame Rows 추가
- Row를 추가한다는 것은 값을 추가하는 것입니다.
- DataFrame의 컬럼값과 동일하게 추가해줘야 합니다.(동일하지 않을 경우 Nan값이 찍히게 됩니다.)
new_row = pd.Series({'Name': 'Bob', 'Age': 22})
df.append(new_row)- 위의 코드와 같이 append를 사용하여 최종적으로 추가해주면 됩니다.
'Data Analyst > ML' 카테고리의 다른 글
| ML - PANDAS(Useful Method) - 1 (0) | 2024.08.31 |
|---|---|
| ML - PANDAS(Condition-Filtering) (0) | 2024.08.29 |
| ML - PANDAS(Data Frame) - 1 (0) | 2024.08.28 |
| ML - Pandas(Series) (1) | 2024.08.27 |
| ML - Pandas(Combining DataFrames) - 2 (0) | 2024.08.22 |
Data Frame - 2
Data Frame 인덱스 선택하기
- column들을 기반으로 선택하는 방법입니다.
- 딕셔너리에서 키값을 넣으면 값이 나오는 방법 처럼 해당 컬럼명을 넣으면 해당 컬럼의 값들이 출력 됩니다.
df['total_bill']- 그리고 위의 코드 결과의 타입은 Series 타입입니다.
- 이번에는 두 개의 컬럼을 가져오겠습니다.
# 여기서 중요한 점은 두 개의 컬럼을 가져오는 경우 이중 대괄호를 사용해야 한다.
df[['total_bill','tip']]- 여기서 위의 코드에서도 말했듯이 두 개 이상의 컬럼을 사용하는 경우에는 이중 대괄호를 사용해야 합니다.
- 이유 : 이중 대괄호를 사용한다는 것은 타입이 DataFrame 값을 출력하는 것입니다.
또 한 가지를 저희는 기억해야 합니다. Series는 1차원 배열이고, DataFrame은 2차원 구조를 가지게 되어있습니다.
즉, 컬럼을 두 개이상 사용한다는 것은 2차원 배열을 사용해야 한다는 것이고 이 말은 DataFrame으로 출력해야 한다는 것입니다.
Data Frame에 새로운 Column값 만들기
- Data Frame에 컬럼을 추가하는 방법은 매우 간단합니다.
# tip_percentage라는 컬럼을 추가하고 값으로는 tip값의 퍼센티지를 넣어주는 코드입니다.
df['tip_percentage'] = 100* df['tip'] / df['total_bill']
df.head()- 맨 뒤에 'tip_percentage'가 추가 된 것을 확인 할 수 있습니다.
Data Frame에 Column 지우기
- Data Frame에 존재하는 컬럼을 제거 하는 방법은 drop을 사용하면 됩니다.
# axis = 0 -> 행
# axis = 1 -> 열
df = df.drop("tip_percentage",axis=1)
df.head()- 맨 뒤의 'tip_percentage'가 삭제 된 것을 확인 할 수 있습니다.
Data Frame에 Index 설정하기
- Data Frame에 인덱스를 설정 하는 방법은 set_index()함수를 사용하면 됩니다.
# Payment ID로 인덱스를 설정
df.set_index('Payment ID')- 'Payment ID'를 기준으로 DataFrame이 바뀌게 됩니다.
- 아래의 코드 결과를 보면 바뀐게 없어 보이지만 해당 인덱스를 기준으로 이제 값이 출력되는 것으로 보일 것입니다.
- reset_index()를 사용하게 되면 설정된 인덱스가 없어지게 됩니다.
Data Frame Rows
- Row값을 조회할 때는 숫자형으로 조회할 때와 문자열로 조회할 때는 서로 다른 함수를 사용합니다.
# Integer Based
df.iloc[0]
# Name Based
df.loc['Sun2959']
- 위의 결과와 같이 해당 인덱스의 데이터의 정보가 출력 됩니다.(1차원 배열이기 때문에 Series 타입!!)
- 여러 Row를 조회 하고 싶을 떄는 인덱스 슬라이싱을 사용해주면 됩니다.
# 인덱스 슬라이싱 사용하여 0~4의 인덱스의 모든 데이터 값을 가져옴
df.iloc[0:4]
# 인덱스 슬라이싱이 아닌 이중 대괄호를 사용하여 name값을 넣어 조회 할수도 있음.
df.loc[['Sun2959','Sun5260']]Data Frame Rows 삭제
- column 삭제와 같이 Row 삭제할 때도 drop을 사용하면 됩니다.
# axis = 0 -> 행
# head()를 통해 삭제된 것을 확인.
df.drop('Sun2959',axis=0).head()
# 만약에 name을 넣지 않고 숫자형을 넣게되면 오류가 발생한다!!
# df.drop(0,axis=0).head()Data Frame Rows 추가
- Row를 추가한다는 것은 값을 추가하는 것입니다.
- DataFrame의 컬럼값과 동일하게 추가해줘야 합니다.(동일하지 않을 경우 Nan값이 찍히게 됩니다.)
new_row = pd.Series({'Name': 'Bob', 'Age': 22})
df.append(new_row)- 위의 코드와 같이 append를 사용하여 최종적으로 추가해주면 됩니다.
'Data Analyst > ML' 카테고리의 다른 글
| ML - PANDAS(Useful Method) - 1 (0) | 2024.08.31 |
|---|---|
| ML - PANDAS(Condition-Filtering) (0) | 2024.08.29 |
| ML - PANDAS(Data Frame) - 1 (0) | 2024.08.28 |
| ML - Pandas(Series) (1) | 2024.08.27 |
| ML - Pandas(Combining DataFrames) - 2 (0) | 2024.08.22 |