Data Frame - 1
- 데이터 분석에 유용한 2차원 데이터 구조입니다.
- 엑셀의 시트나 SQL 테이블과 비슷한 형식을 가지며, 행(row)과 열(column)로 이루어져 있습니다.
- 이를 활용하면 대용량 데이터를 쉽게 조작할 수 있습니다.
Data Frame 생성하기
- pd.DataFrame(data=값, index=인덱스명, column=컬럼명) 이런 형식으로 데이터 프레임을 생성 할 수 있습니다.
- 아래코드를 확인 하겠습니다.
# numpy를 사용하여 난수를 고정시킨 후 4행 3열의 배열을 만들게 된다.
np.random.seed(101)
mydata = np.random.randint(0,101,(4,3))
# 인덱스에 넣을 값 변수에 저장
myindex = ['CA','NY','AZ','TX']
# 컬럼에 넣을 값 변수에 저장
mycolumns = ['Jan','Feb','Mar']
# 데이터프레임 생성
pd.DataFrame(data=mydata,index=myindex,columns=mycolumns)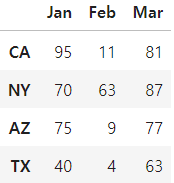
- 위의 그림과 같이 데이터 프레임이 생성된 것을 확인할 수 있습니다.
csv파일을 통해 Data Frame 생성하기
- csv 파일 읽는 방법
df = pd.read_csv('파일명.csv')- 위의 코드를 사용하면 해당 csv파일을 읽어들여 해당 데이터 셋을 DataFrame으로 변환하게 됩니다.
- 그래서 pandas의 DataFrame은 큰 크기의 데이터 셋을 읽어 들여 원하는 대로 바꿀 수 있습니다.
- 그리고 csv 파일 뿐만 아니라, Excel, html, sql 파일도 읽을 수 있습니다. (해당 내용은 다음에 알아보겠습니다.)
DataFrame의 기본 정보 얻기
df.columns : 해당 명령어를 사용하면 해당 DataFrame의 컬럼명들을 모두 가져올 수 있습니다.
df.index : 해당 명령어를 사용하면 해당 DataFrame 의 인덱스의 처음(start), 끝의 수(stop)와 step을 알 수 있습니다.
df.head() : 상위 5개의 DataFrame 값들을 가져옵니다.(데이터프레임을 확인 할 때 자주 사용하는 함수입니다.)
df.tail() : 하위 5개의 DataFrame 값들을 가져옵니다.(head와 tail은 소괄호 안에 아무것도 쓰지 않으면 default값으로 5가 설정 됩니다.)
df.info() : DataFrame의 구조를 빠르게 파악할 수 있는 유용한 함수입니다.
df.describe() : 해당 DataFrame의 count(개수), mean(평균), std(표준편차), min(최솟값), 25%(해당 값 보다 작은 값이 데이터의 25%라는 것을 의미), 50%(중앙값), 75%(상위 25%를 제외한 나머지 75%에 해당하는 값), max(최대값)를 출력해줍니다.
df.transpose() : DataFrame의 행과 열을 바꿔줍니다.
'Data Analyst > ML' 카테고리의 다른 글
| ML - PANDAS(Condition-Filtering) (0) | 2024.08.29 |
|---|---|
| ML - PANDAS(DATA FRAME) - 2 (1) | 2024.08.28 |
| ML - Pandas(Series) (1) | 2024.08.27 |
| ML - Pandas(Combining DataFrames) - 2 (0) | 2024.08.22 |
| ML - Pandas(Combining DataFrames) - 1 (0) | 2024.08.22 |