Series
- 우선, Series는 pandas의 데이터 타입입니다.
- Series는 넘파이 배열(NumPy array)과 매우 비슷합니다(사실 넘파이 배열 객체 위에 구축되어 있습니다).
- 넘파이 배열과 시리즈의 차이점은 시리즈는 축 레이블(axis labels)을 가질 수 있다는 것입니다.
- 즉, 숫자 위치 대신 레이블로 인덱싱할 수 있습니다. 또한 시리즈는 숫자 데이터만 담을 필요가 없고, 임의의 파이썬 객체를 담을 수 있습니다.
- Series에는 여러 옵션 값(매개변수)이 존재한다. (dtype, name, copy들 도 있으나, data와 index에 대해서만 설명 하겠습니다.)
- data : 배열과 유사한 형태, Iterable, 딕셔너리 또는 스칼라 값이 들어갈 수 있으며, 시리즈에 저장된 데이터를 포함합니다.
데이터가 딕셔너리인 경우, 인수의 순서가 유지됩니다.
- index : 배열과 유사한 형태 또는 인덱스(1차원)이며, 값은 해시 가능해야 하며 data와 동일한 길이를 가져야 합니다.
비유일 인덱스 값도 허용됩니다. 제공되지 않으면 기본적으로 RangeIndex(0, 1, 2, ..., n)로 설정됩니다.
데이터가 딕셔너리 형태이고 인덱스가 None인 경우, 데이터의 키가 인덱스로 사용됩니다.
myindex = ['USA','Canada','Mexico']
mydata = [1776,1867,1821]
pd.Series(data=mydata,index=myindex)
# 딕셔너리인 경우
ages = {'Sammy':5,'Frank':10,'Spike':7}
pd.Series(ages)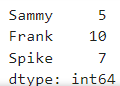
Series 주요 개념
우선, 글로벌 회사의 1분기 및 2분기 가상의 판매 데이터가 있다고 가정하겠습니다.
# 1분기 2분기 판매 데이터
q1 = {'Japan': 80, 'China': 450, 'India': 200, 'USA': 250}
q2 = {'Brazil': 100,'China': 500, 'India': 210,'USA': 260}
# 해당 데이터를 Series로 변환
sales_Q1 = pd.Series(q1)
sales_Q2 = pd.Series(q2)
# 1분기 인덱스를 사용할 때 아래 코드와 같이 'Japan'을 입력하면 설정한 값이 나온다.
# 그러므로 80 출력
sales_Q1['Japan']
# 해당 코드도 마찬가지로 0번 인덱스는 'Japan'을 가르키며 80출력
sales_Q1[0]위의 코드와 같이 인덱스에 키 값을 넣어서 사용해도 가능합니다.
그리고 배열과 비슷하게 0번인덱스로 시작합니다.
Operation(연산)
타입유형이 Series인 변수에 연산을 사용하게 되면 해당 Series에 있는 모든 값들은 연산이 적용됩니다.
sales_Q1 * 2
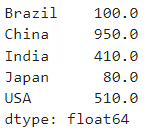
sales_Q1 + sales_Q2
# fill_value는 Pandas의 add 메서드에서 사용되는 매개변수로, 두 개의 시리즈를 더할 때
# 한 쪽 시리즈에만 존재하는 인덱스에 대해 어떤 값을 채울지를 지정하는 역할을 합니다.
sales_Q1.add(sales_Q2,fill_value=0)

'Data Analyst > ML' 카테고리의 다른 글
| ML - PANDAS(Condition-Filtering) (0) | 2024.08.29 |
|---|---|
| ML - PANDAS(DATA FRAME) - 2 (1) | 2024.08.28 |
| ML - PANDAS(Data Frame) - 1 (0) | 2024.08.28 |
| ML - Pandas(Combining DataFrames) - 2 (0) | 2024.08.22 |
| ML - Pandas(Combining DataFrames) - 1 (0) | 2024.08.22 |