Pandas 함수 - (pd.concat([DataFrame, DataFrame], axis=0 or 1)
- Pandas는 두 개의 표에서 행과 열 중 하나라도 동일한 것이 있다면 서로 합칠 수 있다.
- axis = 0 : 행(row)을 기준으로 합친다는 의미이다. (두개의 data frame에서 행이 같은 인덱스라면 그 인덱스를 기준으로 합쳐지게 된다. )
- axis = 1 : 열(column)을 기준으로 합친다는 의미이다.(두개의 data frame에서 열이 같은 인덱스라면 그 인덱스를 기준으로 합쳐지게 된다.)
import numpy as np
import pandas as pd
data_one = {'A':['A0', 'A1', 'A2', 'A3'], 'B':['B0', 'B1', 'B2', 'B3']}
data_two = {'C': ['C0', 'C1', 'C2', 'C3'], 'D': ['D0', 'D1', 'D2', 'D3']}
one = pd.DataFrame(data_one)
two = pd.DataFrame(data_two)
pd.concat([one, two], axis=1)위의 코드를 사용하게 되면 아래의 그림의 결과가 나온다. (동일한 인덱스 0,1,2,3 기준으로 합쳐졌다.)
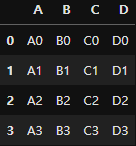
pd.concat([one, two], axis=0)행을 기준으로 합치면 동일한 인덱스가 없지만 합칠 수는 있다.
하지만 결과가 아래의 그림과 같이 Nan 값이 찍히면서 보기 좋지는 않게 출력되게 된다.
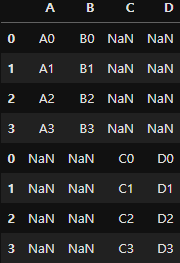
위의 문제를 해결 하기 위해서는 행의 값이 같아야한다. 현재는 A, B, C, D로 모두 다르지만 A, B로 통일한다면 NaN값 없이 알맞게 표가 만들어 질 것이다.
two.columns = one.columns # 컬럼명을 동일하게 바꾸는 코드이다.
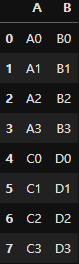
pd.concat([one, two], axis=0)two가 one과 같은 컬럼명을 갖게 된다 (C, D) => (A, B)
아래의 결과와 같이 A, B를 기준으로 합쳐진 것을 확인 할 수 있다.
728x90
'Data Analyst > ML' 카테고리의 다른 글
| ML - PANDAS(Condition-Filtering) (0) | 2024.08.29 |
|---|---|
| ML - PANDAS(DATA FRAME) - 2 (1) | 2024.08.28 |
| ML - PANDAS(Data Frame) - 1 (0) | 2024.08.28 |
| ML - Pandas(Series) (1) | 2024.08.27 |
| ML - Pandas(Combining DataFrames) - 2 (0) | 2024.08.22 |