비지도 학습
학습 데이터에 정답(label)이 없는 상태에서 데이터의 구조를 분석하고 패턴을 찾아내는 기계 학습 방법입니다.
주로 데이터의 숨겨진 구조를 파악하거나, 비슷한 특성을 가진 데이터들을 군집화하는 데 사용됩니다.
비지도 학습에서는 모델이 데이터를 학습하면서 정답을 맞추는 것이 아니라, 데이터의 특징을 추출하거나 그룹을 구분합니다.
비지도 학습 대표적인 사례
군집 Clustering : 비슷한 샘플을 모음
이상치 탐지 Outlier detection : 정상 데이터가 어떻게 보이는지 학습, 비정상 샘플을 감지
밀도 추정 : 데이터셋의 확률 밀도 함수 Probability Density Function PDF를 추정, 이상치 탐지 등에 사용
K-Means
군집 중심 이라는 임의의 지점을 선택해서 해당 중심에 가장 가까운 포인트들을 선택하는 군집화
일반적인 군집화에서 가장 많이 사용되는 기법
거리 기반 알고리즘으로 속성의 개수가 많을 경우 군집화의 정확도가 떨어짐
원리
- 초기 중심점 설정
- 각 데이터는 할당된 평균값으로 중심점 이동
- 각 데이터는 이동된 중심점 기준으로 가장 가까운 중심점에 소속
- 다시 중심점에 할당된 데이터들의 평균값으로 중심점 이동
- 데이터들의 중심점 소속 변경이 없으면 종료
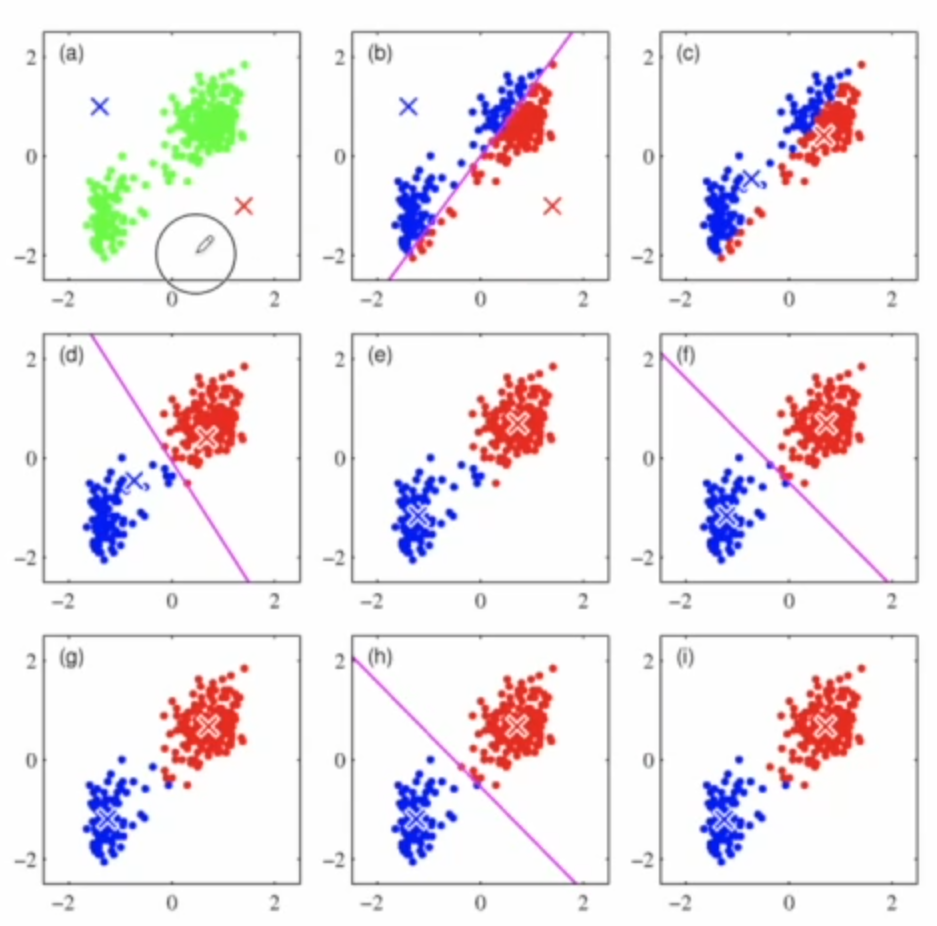
알아야 할 것!!

라벨 확인 할 때 1, 2, 0으로 구성되어 있는데 이 label은 그저 우리가 3개로 나눠달라해서 나눈 것일 뿐 실제 Label값이 아니다!!
군집 평가
- 분류기는 평가 기준(정답)을 가지고 있지만, 군집은 그렇지 않습니다.
- 군집 결과를 평가하기 위해 실루엣 분석을 많이 활용합니다.
실루엣 분석
- 실루엣 분석은 각 군집 간의 거리가 얼마나 효율적으로 분리돼어 있는지 나타냅니다.
- 다른 군집과는 거리가 떨어져 있고 동일 군집간의 데이터는 서로 가깝게 잘 뭉쳐 있는지 확인 합니다.
- 군집화가 잘 되어 있을 수록 개별 군집은 비슷한 정도의 여유공간을 가지고 있습니다..
- 실루엣 계수 : 개별 데이터가 가지는 군집화 지표입니다.
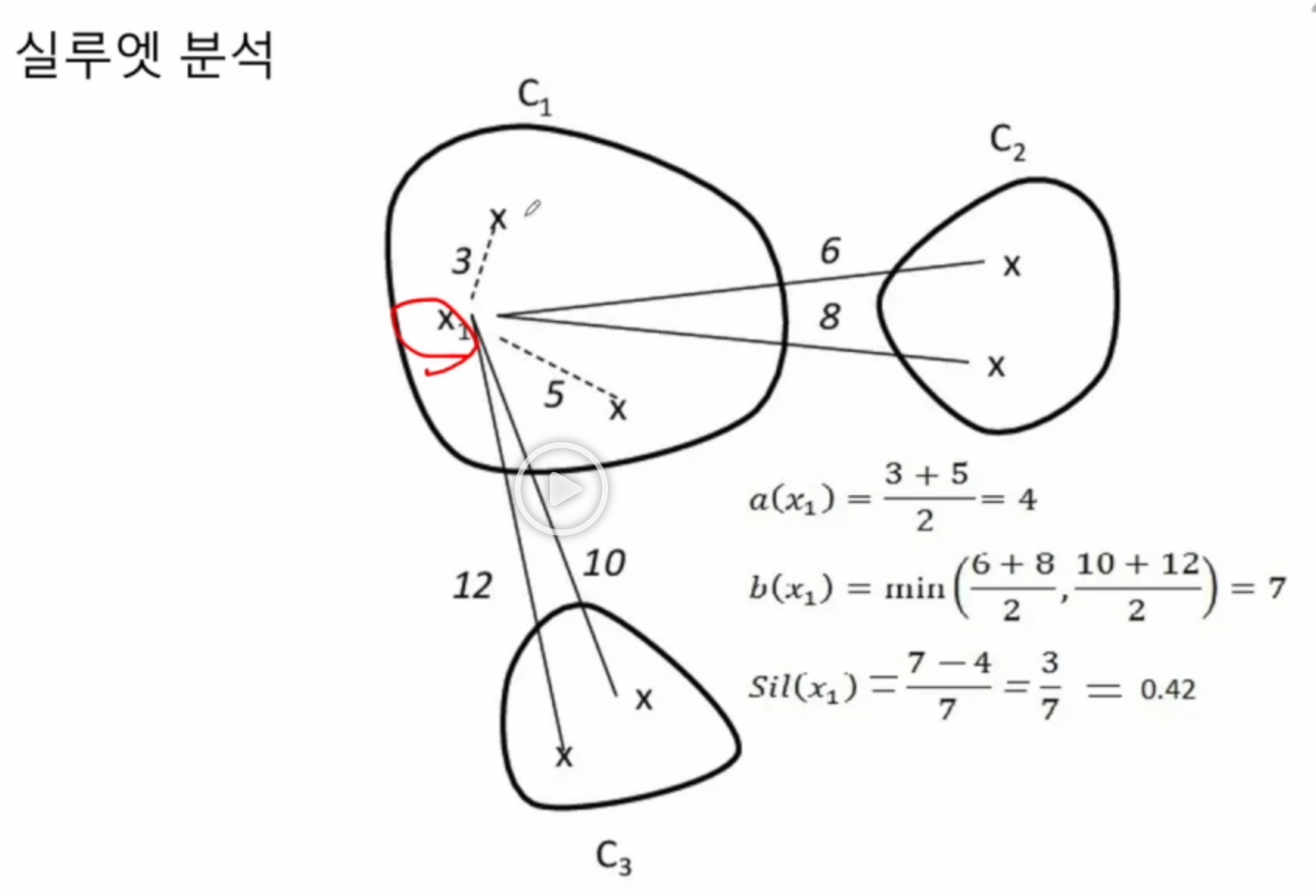
실루엣 계수
- 개별 데이터가 할당된 군집 내 데이터와 얼마나 가깝게 군집화 되어있는지, 그리고 다른 군집에 있는 데이터와는 얼마나 멀리 분리되어 있는지를 수치로 나타냅니다. 군집이 잘 분리되었다는 것은 동일한 군집 내에서의 데이터는 서로 가깝게 위치해있으며 다른 군집과의 거리는 멀음을 의미합니다. 값이 크다면 군집화의 성능이 좋다고 해석할 수 있습니다.
- 실루엣 계수는 -1에서 1 사이의 값을 가지며 1에 가까울 수록 근처 군집과 멀리 떨어져 있음을, 0에 가까울수록 근처 군집과 가까움을 의미합니다. -(마이너스)이면 아예 다른 군집에 데이터가 할당됐음을 의미합니다.
- 전체 실루엣 스코어와 더불어 개별 군집의 평균값의 편차가 크지 않은 경우에만 전체 군집화 성능이 좋다고 판단할 가능성이 생깁니다. 개별 군집의 실루엣 스코어가 전체 실루엣 스코어와 크게 다르지 않아야 된다는 뜻입니다.
- 전체 실루엣 스코어가 클지라도 개별 군집의 실루엣 스코어가 들쭉날쭉하다면 군집화가 잘되었다고 할 수 없다는 의미이죠.
이상으로 Clustering(군집화) 개념과 군집화를 평가할 때 사용하는 실루엣에 대해 알아보았으며 다음 글에서 IRIS 품종 구별 데이터를 이용하여 군집화를 해보겠습니다.
이 글은 제로베이스 데이터 분석 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.
728x90
'Data Analyst > ML' 카테고리의 다른 글
| [Zero-base] 군집화(Clustering) - 2 (0) | 2024.10.11 |
|---|---|
| [Zero-base] 주성분 분석(PCA, Principal Component Analysis) - 2 (3) | 2024.10.10 |
| [Zero-base] 주성분 분석(PCA, Principal Component Analysis) - 1 (0) | 2024.10.10 |
| [Zero-Base] 앙상블 기법 - 2 (1) | 2024.10.08 |
| [Zero-base] 앙상블 기법 - 1 (3) | 2024.10.08 |