1. IRIS 데이터를 가져오겠습니다.
from sklearn.datasets import load_iris
# 해당 데이터에는 Label이 없습니다.
iris = load_iris()
# 특성 이름을 가져옵니다.
cols = [each[:-5] for each in iris.feature_names]
import pandas as pd
iris_df = pd.DataFrame(iris.data, columns=cols)
iris_df.head()
# 중요 특성 2개만 사용하겠습니다.
features = iris_df[['petal length', 'petal width']]위의 코드와 같이 데이터 프레임을 만들기위해 컬럼명들을 가져오고
중요한 특성 두 개만 가지고 오는 것을 확인 할 수 있습니다. (제 블로그 IRIS 품종 구별 글 보시면 확인 할 수 있습니다.)
2. KMeans 사용하여 데이터 훈련 시키기
from sklearn.cluster import KMeans
model = KMeans(n_clusters=3) # 몇 개로 구별 할 것인지
model.fit(features)KMeans를 사용할 때 n_clusters를 사용하는데 이 것은 데이터를 몇 개로 구별할 것인지 넣는 변수입니다.
저는 3개로 구별 하기 위해 3을 넣어 주었습니다.
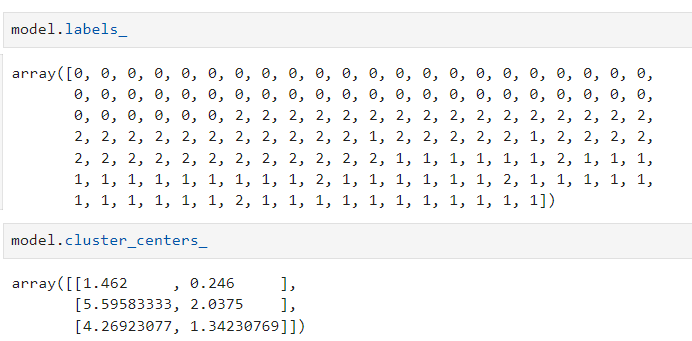
그리고 잘 구분됬는지 labels_를 이용하여 어떻게 구분 되었는지 확인해보았습니다.
각 군집들의 center값에 대한 x와 y값을 확인하기 위해 cluster_centers_를 사용하였습니다.
3. 찾은 데이터들의 분포와 중심값 시각화 하기
# 찾은 Label 기존의 데이터와 합쳐주기
predict = pd.DataFrame(model.predict(features), columns=['cluster'])
feature = pd.concat([features, predict], axis=1)
import matplotlib.pyplot as plt
# center 표현하기위해 x와 y값 DataFrame에 넣어주기
centers = pd.DataFrame(model.cluster_centers_, columns=['petal length', 'petal width'])
center_x = centers['petal length']
center_y = centers['petal width']
# 시각화
plt.figure(figsize=(12, 7))
plt.scatter(feature['petal length'], feature['petal width'], c=feature['cluster'], alpha=0.5)
plt.scatter(center_x, center_y, s=50, marker='D', c='r')
plt.show()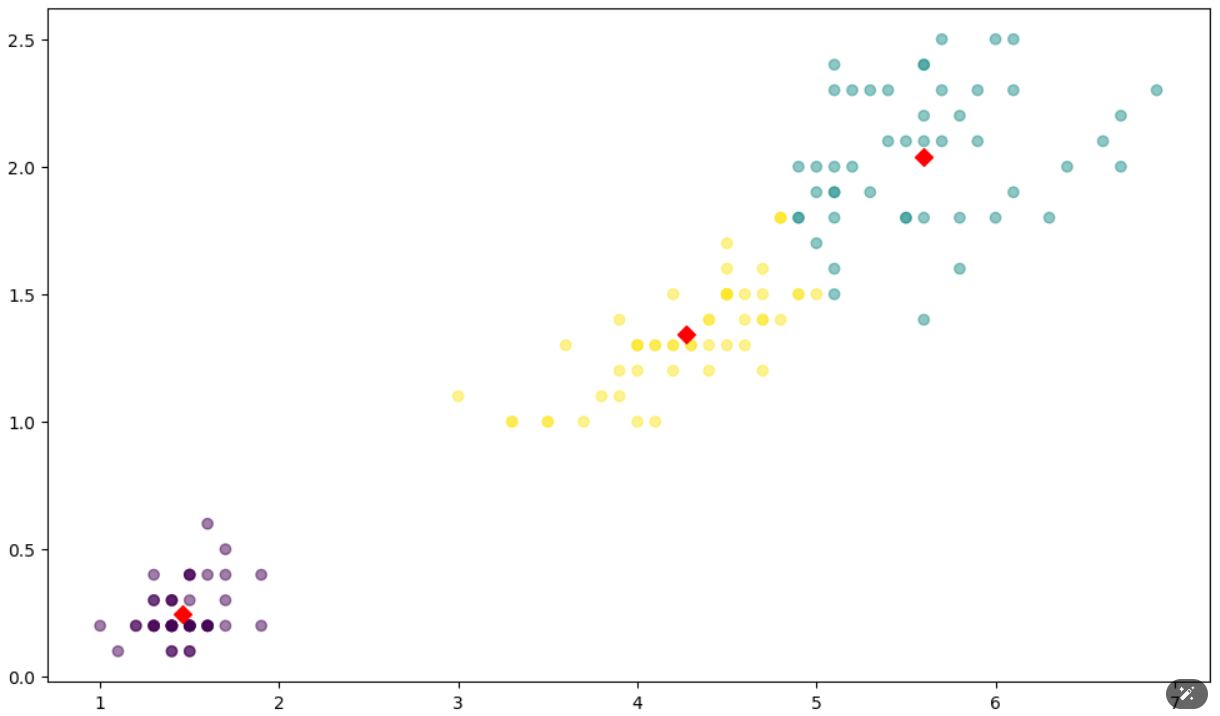
우선 cneter의 x와 y값을 DataFrame으로 만들어 줍니다. 그리고 matplotlib를 사용하여 scatter그래프로 시각화해보았습니다.
이렇게 보니 중심값도 잘 잡혀있고 군집화도 잘 되어 구별이 잘 되는 것 같습니다.
하지만 제대로 확인하려면 실루엣 분석을 해야 합니다.
4. 실루엣 분석하기
from sklearn.metrics import silhouette_samples, silhouette_score
avg_value = silhouette_score(iris_df, iris_df['cluster'])
score_value = silhouette_samples(iris_df, iris_df['cluster'])
def visualize_silhouette(cluster_lists, X_features):
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_samples, silhouette_score
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import math
n_cols = len(cluster_lists)
fig, axs = plt.subplots(figsize=(4*n_cols, 4), nrows=1, ncols=n_cols)
for ind, n_cluster in enumerate(cluster_lists):
clusterer = KMeans(n_clusters = n_cluster, max_iter=500, random_state=0)
cluster_labels = clusterer.fit_predict(X_features)
sil_avg = silhouette_score(X_features, cluster_labels)
sil_values = silhouette_samples(X_features, cluster_labels)
y_lower = 10
axs[ind].set_title('Number of Cluster : '+ str(n_cluster)+'\n' \
'Silhouette Score :' + str(round(sil_avg,3)) )
axs[ind].set_xlabel("The silhouette coefficient values")
axs[ind].set_ylabel("Cluster label")
axs[ind].set_xlim([-0.1, 1])
axs[ind].set_ylim([0, len(X_features) + (n_cluster + 1) * 10])
axs[ind].set_yticks([]) # Clear the yaxis labels / ticks
axs[ind].set_xticks([0, 0.2, 0.4, 0.6, 0.8, 1])
for i in range(n_cluster):
ith_cluster_sil_values = sil_values[cluster_labels==i]
ith_cluster_sil_values.sort()
size_cluster_i = ith_cluster_sil_values.shape[0]
y_upper = y_lower + size_cluster_i
color = cm.nipy_spectral(float(i) / n_cluster)
axs[ind].fill_betweenx(np.arange(y_lower, y_upper), 0, ith_cluster_sil_values, \
facecolor=color, edgecolor=color, alpha=0.7)
axs[ind].text(-0.05, y_lower + 0.5 * size_cluster_i, str(i))
y_lower = y_upper + 10
axs[ind].axvline(x=sil_avg, color="red", linestyle="--")
import numpy as np
visualize_silhouette([2,3,4], iris.data)아래 그림은 클러스터 개수를 2, 3, 4개로 설정했을 때의 실루엣 점수를 시각화한 것입니다.
그리고 빨간 점선이 실루엣 계수들의 평균입니다.
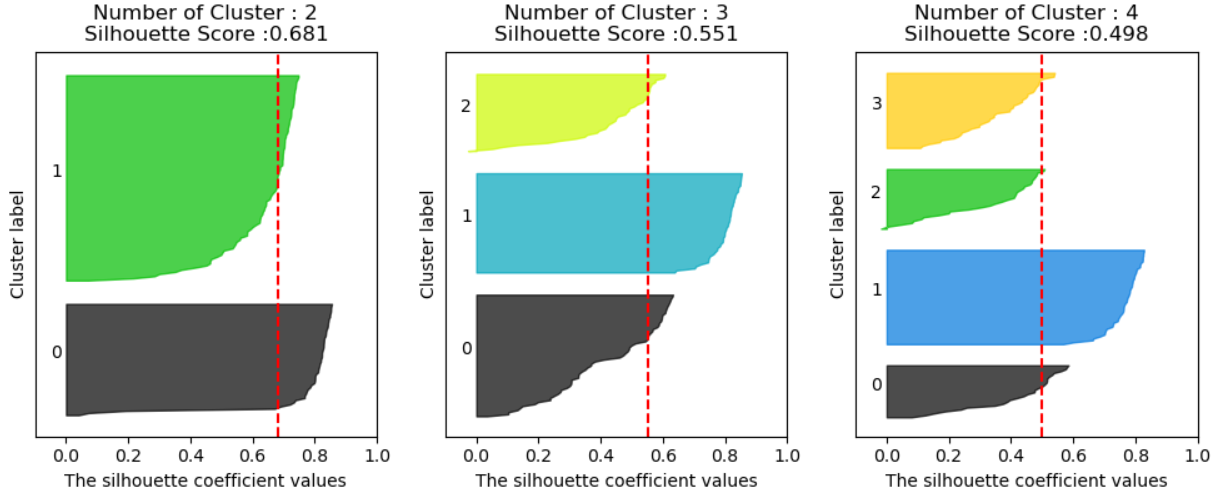
(1) 클러스터 2개일 때: 실루엣 점수 0.681
- 실루엣 점수는 0.681로, 가장 높은 점수를 기록했습니다.
- 데이터가 2개의 그룹으로 나뉠 때 각 클러스터 간의 구분이 가장 명확하다는 것을 의미합니다.
- 하지만, 실제 데이터 분석의 목표는 3개의 클러스터로 나누는 것이기 때문에 이 값이 가장 높다고 하더라도, 현실적으로 적절한 클러스터 개수는 아닙니다.
(2) 클러스터 3개일 때: 실루엣 점수 0.551
- 실루엣 점수는 0.551로, 클러스터 2개일 때보다 약간 낮지만, 정답은 3개의 클러스터로 나누는 것입니다.
- 이는 일부 데이터가 경계에 걸쳐 있을 수 있지만, 전체적으로 보면 3개의 클러스터로 나누는 것이 의미가 있습니다.
- 실루엣 점수가 다소 낮더라도, 클러스터링의 목적과 데이터의 실제 분포에 맞춰 3개의 클러스터를 선택하는 것이 올바른 결정입니다.
(3) 클러스터 4개일 때: 실루엣 점수 0.498
- 실루엣 점수는 0.498로 가장 낮습니다.
- 이는 클러스터 개수가 과도하게 많아졌고, 일부 데이터가 잘못된 클러스터에 포함될 가능성이 높다는 것을 의미합니다.
4. 결론:
실루엣 점수를 기반으로 클러스터 수를 평가할 때, 2개의 클러스터가 가장 높은 점수를 기록했습니다. 그러나 정답은 3개의 클러스터라는 것을 고려해야 합니다. 실루엣 점수만으로 클러스터 개수를 결정하는 것이 아니라, 데이터의 특성과 분석 목표에 맞춰 클러스터 수를 선택하는 것이 중요합니다.
이상으로 KMeans를 활용한 데이터 군집화 글을 마치겠습니다.
이 글은 제로베이스 데이터 분석 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.
'Data Analyst > ML' 카테고리의 다른 글
| [Zero-base] 군집화(Clustering) - 1 (0) | 2024.10.11 |
|---|---|
| [Zero-base] 주성분 분석(PCA, Principal Component Analysis) - 2 (3) | 2024.10.10 |
| [Zero-base] 주성분 분석(PCA, Principal Component Analysis) - 1 (0) | 2024.10.10 |
| [Zero-Base] 앙상블 기법 - 2 (1) | 2024.10.08 |
| [Zero-base] 앙상블 기법 - 1 (3) | 2024.10.08 |
1. IRIS 데이터를 가져오겠습니다.
from sklearn.datasets import load_iris
# 해당 데이터에는 Label이 없습니다.
iris = load_iris()
# 특성 이름을 가져옵니다.
cols = [each[:-5] for each in iris.feature_names]
import pandas as pd
iris_df = pd.DataFrame(iris.data, columns=cols)
iris_df.head()
# 중요 특성 2개만 사용하겠습니다.
features = iris_df[['petal length', 'petal width']]위의 코드와 같이 데이터 프레임을 만들기위해 컬럼명들을 가져오고
중요한 특성 두 개만 가지고 오는 것을 확인 할 수 있습니다. (제 블로그 IRIS 품종 구별 글 보시면 확인 할 수 있습니다.)
2. KMeans 사용하여 데이터 훈련 시키기
from sklearn.cluster import KMeans
model = KMeans(n_clusters=3) # 몇 개로 구별 할 것인지
model.fit(features)KMeans를 사용할 때 n_clusters를 사용하는데 이 것은 데이터를 몇 개로 구별할 것인지 넣는 변수입니다.
저는 3개로 구별 하기 위해 3을 넣어 주었습니다.
그리고 잘 구분됬는지 labels_를 이용하여 어떻게 구분 되었는지 확인해보았습니다.
각 군집들의 center값에 대한 x와 y값을 확인하기 위해 cluster_centers_를 사용하였습니다.
3. 찾은 데이터들의 분포와 중심값 시각화 하기
# 찾은 Label 기존의 데이터와 합쳐주기
predict = pd.DataFrame(model.predict(features), columns=['cluster'])
feature = pd.concat([features, predict], axis=1)
import matplotlib.pyplot as plt
# center 표현하기위해 x와 y값 DataFrame에 넣어주기
centers = pd.DataFrame(model.cluster_centers_, columns=['petal length', 'petal width'])
center_x = centers['petal length']
center_y = centers['petal width']
# 시각화
plt.figure(figsize=(12, 7))
plt.scatter(feature['petal length'], feature['petal width'], c=feature['cluster'], alpha=0.5)
plt.scatter(center_x, center_y, s=50, marker='D', c='r')
plt.show()우선 cneter의 x와 y값을 DataFrame으로 만들어 줍니다. 그리고 matplotlib를 사용하여 scatter그래프로 시각화해보았습니다.
이렇게 보니 중심값도 잘 잡혀있고 군집화도 잘 되어 구별이 잘 되는 것 같습니다.
하지만 제대로 확인하려면 실루엣 분석을 해야 합니다.
4. 실루엣 분석하기
from sklearn.metrics import silhouette_samples, silhouette_score
avg_value = silhouette_score(iris_df, iris_df['cluster'])
score_value = silhouette_samples(iris_df, iris_df['cluster'])
def visualize_silhouette(cluster_lists, X_features):
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_samples, silhouette_score
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import math
n_cols = len(cluster_lists)
fig, axs = plt.subplots(figsize=(4*n_cols, 4), nrows=1, ncols=n_cols)
for ind, n_cluster in enumerate(cluster_lists):
clusterer = KMeans(n_clusters = n_cluster, max_iter=500, random_state=0)
cluster_labels = clusterer.fit_predict(X_features)
sil_avg = silhouette_score(X_features, cluster_labels)
sil_values = silhouette_samples(X_features, cluster_labels)
y_lower = 10
axs[ind].set_title('Number of Cluster : '+ str(n_cluster)+'\n' \
'Silhouette Score :' + str(round(sil_avg,3)) )
axs[ind].set_xlabel("The silhouette coefficient values")
axs[ind].set_ylabel("Cluster label")
axs[ind].set_xlim([-0.1, 1])
axs[ind].set_ylim([0, len(X_features) + (n_cluster + 1) * 10])
axs[ind].set_yticks([]) # Clear the yaxis labels / ticks
axs[ind].set_xticks([0, 0.2, 0.4, 0.6, 0.8, 1])
for i in range(n_cluster):
ith_cluster_sil_values = sil_values[cluster_labels==i]
ith_cluster_sil_values.sort()
size_cluster_i = ith_cluster_sil_values.shape[0]
y_upper = y_lower + size_cluster_i
color = cm.nipy_spectral(float(i) / n_cluster)
axs[ind].fill_betweenx(np.arange(y_lower, y_upper), 0, ith_cluster_sil_values, \
facecolor=color, edgecolor=color, alpha=0.7)
axs[ind].text(-0.05, y_lower + 0.5 * size_cluster_i, str(i))
y_lower = y_upper + 10
axs[ind].axvline(x=sil_avg, color="red", linestyle="--")
import numpy as np
visualize_silhouette([2,3,4], iris.data)아래 그림은 클러스터 개수를 2, 3, 4개로 설정했을 때의 실루엣 점수를 시각화한 것입니다.
그리고 빨간 점선이 실루엣 계수들의 평균입니다.
(1) 클러스터 2개일 때: 실루엣 점수 0.681
- 실루엣 점수는 0.681로, 가장 높은 점수를 기록했습니다.
- 데이터가 2개의 그룹으로 나뉠 때 각 클러스터 간의 구분이 가장 명확하다는 것을 의미합니다.
- 하지만, 실제 데이터 분석의 목표는 3개의 클러스터로 나누는 것이기 때문에 이 값이 가장 높다고 하더라도, 현실적으로 적절한 클러스터 개수는 아닙니다.
(2) 클러스터 3개일 때: 실루엣 점수 0.551
- 실루엣 점수는 0.551로, 클러스터 2개일 때보다 약간 낮지만, 정답은 3개의 클러스터로 나누는 것입니다.
- 이는 일부 데이터가 경계에 걸쳐 있을 수 있지만, 전체적으로 보면 3개의 클러스터로 나누는 것이 의미가 있습니다.
- 실루엣 점수가 다소 낮더라도, 클러스터링의 목적과 데이터의 실제 분포에 맞춰 3개의 클러스터를 선택하는 것이 올바른 결정입니다.
(3) 클러스터 4개일 때: 실루엣 점수 0.498
- 실루엣 점수는 0.498로 가장 낮습니다.
- 이는 클러스터 개수가 과도하게 많아졌고, 일부 데이터가 잘못된 클러스터에 포함될 가능성이 높다는 것을 의미합니다.
4. 결론:
실루엣 점수를 기반으로 클러스터 수를 평가할 때, 2개의 클러스터가 가장 높은 점수를 기록했습니다. 그러나 정답은 3개의 클러스터라는 것을 고려해야 합니다. 실루엣 점수만으로 클러스터 개수를 결정하는 것이 아니라, 데이터의 특성과 분석 목표에 맞춰 클러스터 수를 선택하는 것이 중요합니다.
이상으로 KMeans를 활용한 데이터 군집화 글을 마치겠습니다.
이 글은 제로베이스 데이터 분석 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.
'Data Analyst > ML' 카테고리의 다른 글
| [Zero-base] 군집화(Clustering) - 1 (0) | 2024.10.11 |
|---|---|
| [Zero-base] 주성분 분석(PCA, Principal Component Analysis) - 2 (3) | 2024.10.10 |
| [Zero-base] 주성분 분석(PCA, Principal Component Analysis) - 1 (0) | 2024.10.10 |
| [Zero-Base] 앙상블 기법 - 2 (1) | 2024.10.08 |
| [Zero-base] 앙상블 기법 - 1 (3) | 2024.10.08 |