[Zero-base] Precision and Recall
Precision and Recall
Precision(정밀도) : 양성이라고 예측한 것에서 맞힌 비율입니다.
Recall(재현율) : 참인 데이터들 중에서 참이라고 예측한 비율입니다.(TPR(True Positvie Rate))
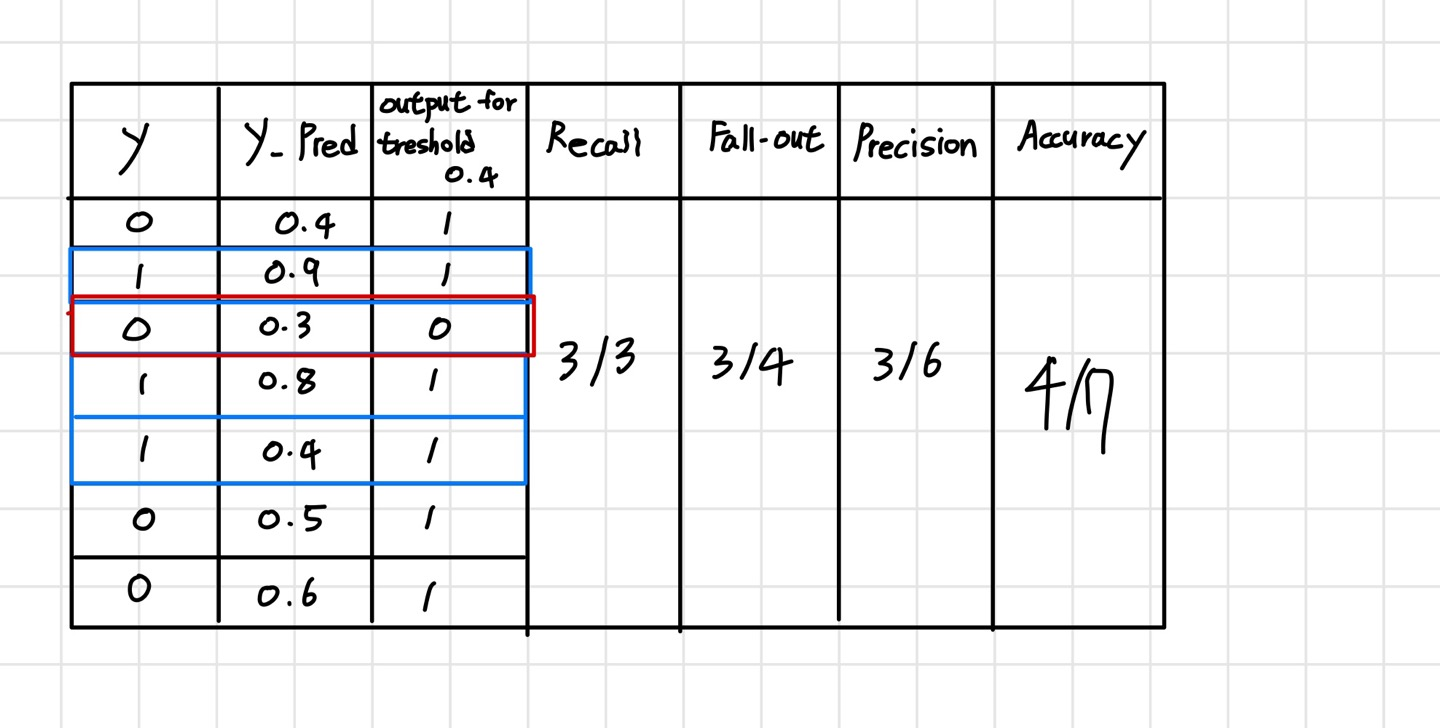
위의 그림으로 보면 precision과 Recall의 확률들이 어떻게 나오는 지 확인 가능합니다. 그리고
https://hmm06.tistory.com/51 해당 페이지를 확인하시면 precision과 recall 그리고 Roc Curve에 대한 설명이 적혀있습니다.
[Zero-base] Scaling & 분류 모델 평가
ScalingLabel Encoder글자를 만나면 숫자로 바꿔준다.글자로 되어있는 특성(feature)들을 다 숫자로 바꿔야만 머신러닝 딥러닝이 잘 동작한다.1. 우선 데이터를 만들어 줍니다.import pandas as pddf = pd.DataFram
hmm06.tistory.com
Classifier_Report
Accuracy로만 보기에는 부족할 경우 사용하는 라이브러리 입니다.
1에 대한 Recall(실제 1인 것 중에서 모델이 1로 정확히 분류한 비율)과 Precision(모델이 1로 분류한 것 중에서 실제로 1인 비율)을 살펴보면, 모델이 1을 잘 맞췄다는 것을 알 수 있습니다.
하지만, 0에 대한 Precision과 Recall을 살펴보면, 모델이 0을 분류한 비율을 보실 수 있습니다.
이러한 분석을 통해, 모델이 특정 클래스(여기서는 1)에 대해서는 좋은 성능을 보이는 반면, 다른 클래스(여기서는 0)에 대해서는 성능이 떨어짐을 알 수 있습니다.
사용예시:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# wine 데이터 활용
wine_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/refs/heads/master/dataset/wine.csv'
wine = pd.read_csv(wine_url, index_col=0)
wine['taste'] = [1. if grade > 5 else 0. for grade in wine['quality']]
X = wine.drop(['taste', 'quality'], axis=1)
y = wine['taste']
# 훈련세트 테스트 세트 분류
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
# 로지스틱 회귀로 정확도 검사
lr = LogisticRegression(solver='liblinear', random_state=13)
lr.fit(X_train, y_train)
y_pred_tr = lr.predict(X_train)
y_pred_test = lr.predict(X_test)
print('Train Acc:', accuracy_score(y_train, y_pred_tr))
print('Test Acc:', accuracy_score(y_test, y_pred_test))
# Classifier_Report를 통해 1과 0에 대한 확률 알아내기
from sklearn.metrics import classification_report
print(classification_report(y_test, lr.predict(X_test))) # 코드결과
precision recall f1-score support
0.0 0.68 0.57 0.62 477
1.0 0.77 0.84 0.81 823
accuracy 0.74 1300
macro avg 0.73 0.71 0.71 1300
weighted avg 0.74 0.74 0.74 1300맨 아래 두 줄에 집중해주시면 될 것 같습니다. 라이브러리 classifier_report를 사용하여 1과 0에 대한 precision과 recall 등 모델 성능에 대한 평가를 다양하게 볼 수 있는 것을 확인 하실 수 있습니다.
Confusion Metrics
해당 라이브러리를 사용하시면 아래의 구조처럼 나옵니다. 각 값에서 의미하는 것은 아래의 보기와 같습니다.
[100, 100] [실제 0 중에서 0을 맞힌 개수, 실제 0중에서 1이라 한 개수]
[100, 100] [실제 1 중에서 0이라한 개수, 실제 1중에서 1로 맞힌 개수]
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test, lr.predict(X_test))array([[274, 203],
[129, 694]], dtype=int64)위의 결과와 같이 맞힌 개수와 틀린 개수를 확인 하실 수 있습니다.
Precision Recall Curve
precision-recall 곡성의 특성 :
클래스 1을 "양성"으로 취급하며, 이 곡선은 주로 양성 클래스(1)의 성능을 평가하는데 사용됩니다.
클래스 0에 대한 확률은 부정 클래스에 대한 성능 평가에 도움이 되지만, 많은 실제 시나리오에서는 클래스 1에 대한 성능이 더 중요한 경우가 많습니다.
import matplotlib.pyplot as plt
from sklearn.metrics import precision_recall_curve
%matplotlib inline
plt.figure(figsize=(10, 8))
pred = lr.predict_proba(X_test)[:,1] # 양성 클래스를 확인하는 커브 그래프이기 때문에 1값인 값만 뽑아낸 것이다.
precisions, recalls, thresholds = precision_recall_curve(y_test, pred)
plt.plot(thresholds, precisions[:len(thresholds)], label='precision')
plt.plot(thresholds, recalls[:len(thresholds)], label='recall')
plt.grid()
plt.legend()
plt.show()
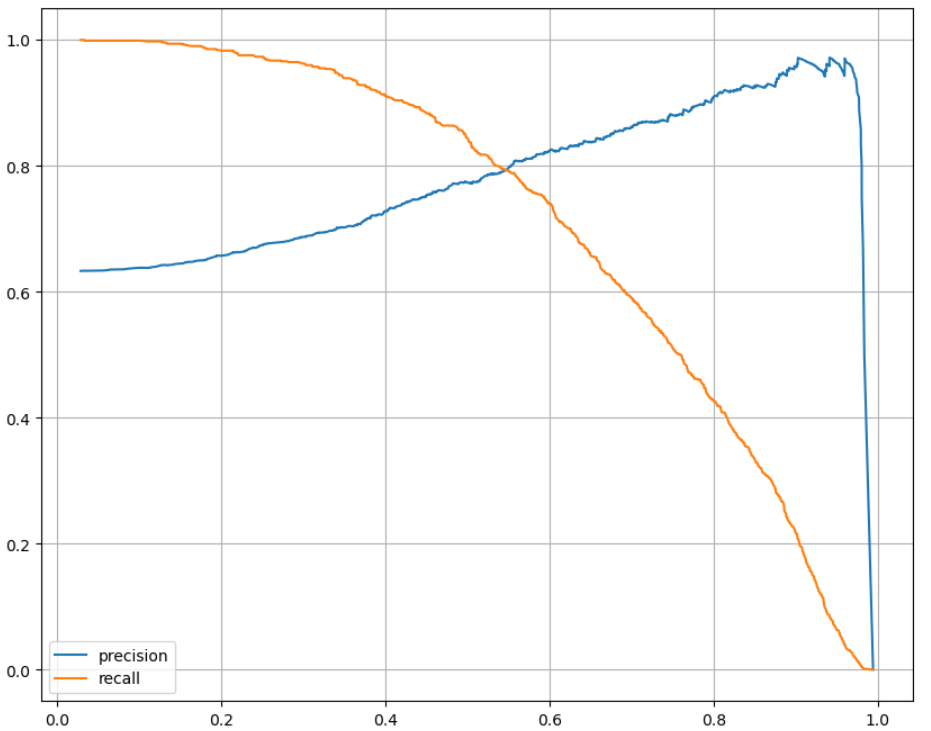
위의 그래프처럼 threshold(임계값)에 따라 변화하는 Precision과 Recall의 관계를 보여주고 있습니다.
X축 : threshold(임계값)
Y축 : Precision과 Recall
Threshold 바꾸기 - Binarizer
바꾼 threshold의 값을 비교한 결과 위에서 했던 결과와 달라진 것을 확인 할 수 있습니다.
threshold를 우리가 바꾸어서 적용하는 것이 좋은 것은 아니므로, 이러한 기능이 있다는 것만 알아두면 좋겠습니다.
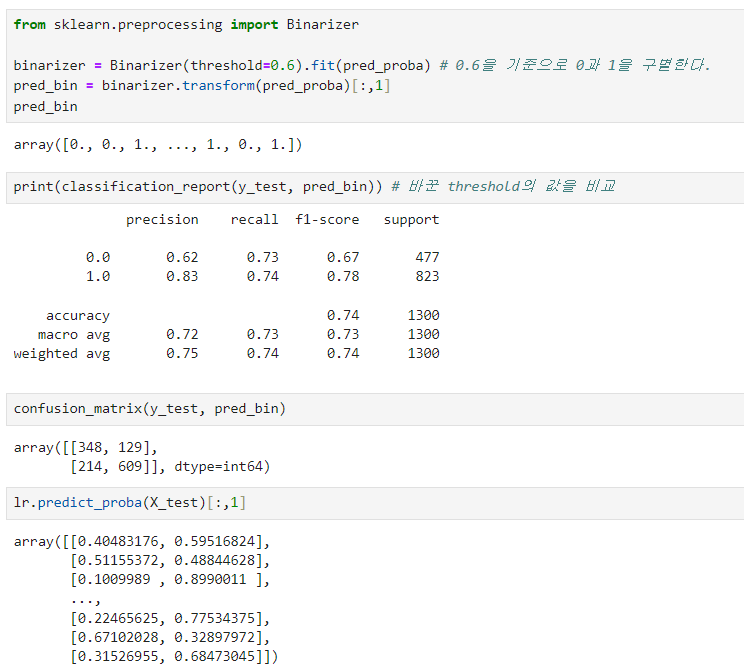
Binarizer를 활용하여 Threshold를 0.6으로 바꾼 결과 0과 1에 대한 확률들이 바뀐것을 확인 할 수 있습니다.
이번 글은 가볍게 정확도로만 평가를 못할 경우 사용하는 함수와 threshold에 따른 recall과 precision의 변화를 알아보았습니다.
이상입니다.
이 글은 제로베이스 데이터 분석 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.