1. Fandango의 표시된 점수와 실제 사용자 평점 비교
먼저 Fandango 평점을 탐색하여 우리의 분석이 기사의 결론과 부합하는지 확인해 봅시다.
# fandango_scrape.csv 파일 읽기
fandango = pd.read_csv("fandango_scrape.csv")
# head()하여 상위 5개 데이터 보기
fandango.head()
# info()사용하여 데이터 내용 확인하기
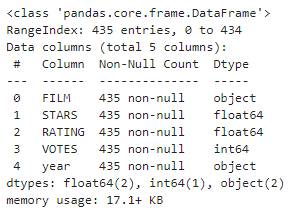
fandango.info()
# describe()사용하여 계산 결과 확인하기
fandango.describe()해당 작업을 해본 결과 컬럼은 FILM, STARS, RATING, VOTES가 있는 것을 확인 하였으며, 총 504개의 행이 존재한다는 것을 알 수 있었으며 4개의 컬럼에서는 NaN값이 없는 것도 확인 되었습니다.
이번에는 영화의 VOTES와 RATING 사이의 관계를 탐색해 봅시다.
RATING과 VOTES 간의 관련을 보여주는 산점도를 만들어 볼 것입니다.
# seaborn 사용하여 산점도 그래프를 만들었습니다.
fig = plt.figure(figsize=(14,6))
sns.scatterplot(fandango,x='RATING',y='VOTES')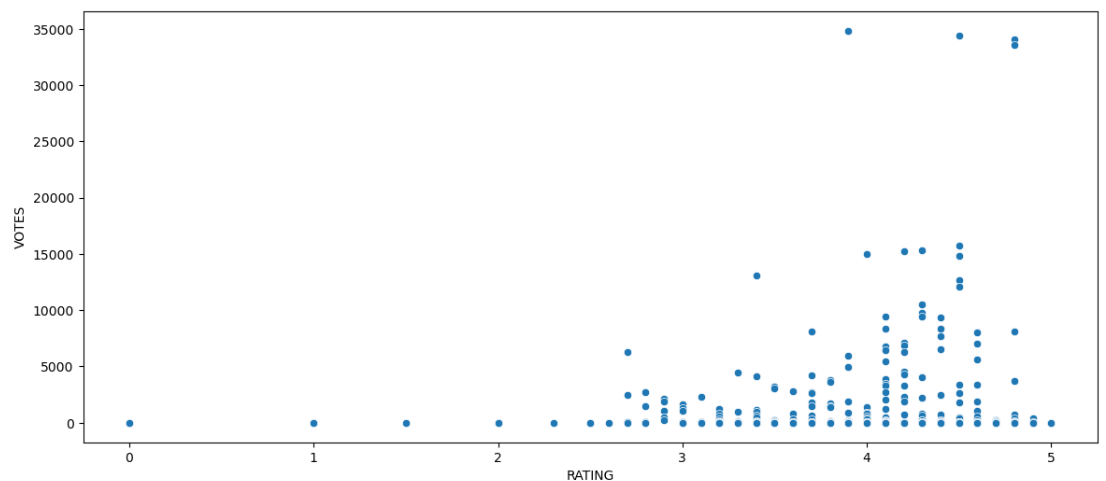
그림을 보면 VOTES가 많은 것이 몇 개 있는 것으로 보아 투표 평균 그래프가 치우쳐져 그려질 수도 있다는 생각을 하였습니다.( right-skewed )
그리고 저는 해당 그래프를 보면 투표 수가 많을 수록 RATING에 대한 결과는 신뢰성이 올라 갈 거라는 추측을 하겠습니다. 예시를 확인 하겠습니다..
ex) 영화에 4점 후반 평가를 한 투표 수가 높의면 해당 영화는 좋은 영화로 볼 수 있다.
이번에 할 것은 위에서 설명 했던 것처럼 컬럼 간 상관관계를 확인 해봐야 할 거 같아서 corr()함수를 사용해보겠습니다.
corr_columns = ['STARS','RATING','VOTES']
corr_fandango = fandango[corr_columns].corr()
corr_fandango
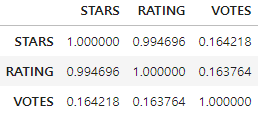
여기서 확인 되는 것은 제가 위에서 VOTES와 RATING에 대한 상관관계가 높을 줄 알았으나, 0.1점대로 매우 낮게 측정되었습니다. 그럼 제가 추측한 결과는 틀린 것으로 확인되었습니다.
그리고 VOTES는 어떤 컬럼과도 큰 상관관계가 없는 거 같습니다.
현재 FILM의 값을 보면 TITLE_NAME(YEAR) 이런 형식으로 되어있습니다.
그래서, 제목 문자열에서 연도를 제거하고, YEAR라는 새로운 열을 연도로 설정하겠습니다.
for idx, row in fandango.iterrows():
# 제목에서 빈칸 있는 경우 연도 앞에서 짜르는 부분
title_year = row['FILM'].split(' ')
# 짤렸던 제목들 다시 합치기
n = 0
if len(row['FILM']) > 2:
n = len(title_year) - 1
else :
n = 1
title = ' '.join(title_year[:n])
# 제목 바꾸기
fandango.loc[idx, 'FILM'] = title
# (year) -> 괄호 제거 후 year를 int형으로 변환
year = title_year[len(title_year) - 1].replace('(','').replace(')','')
fandango.loc[idx, 'year'] = year
fandango.head()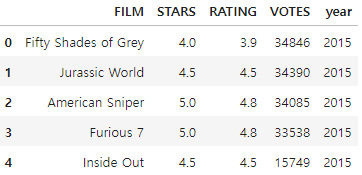
위의 사진과 같이 year컬럼을 생성하고 film에서의 연도는 제거하였습니다.
이번에는 연도별 영화 수를 이용한 그래프를 만들어 보겠습니다.
fig = plt.figure(figsize=(8, 6))
count.plot(kind='bar')
plt.ylabel('count')
plt.xticks(rotation=0)
plt.show()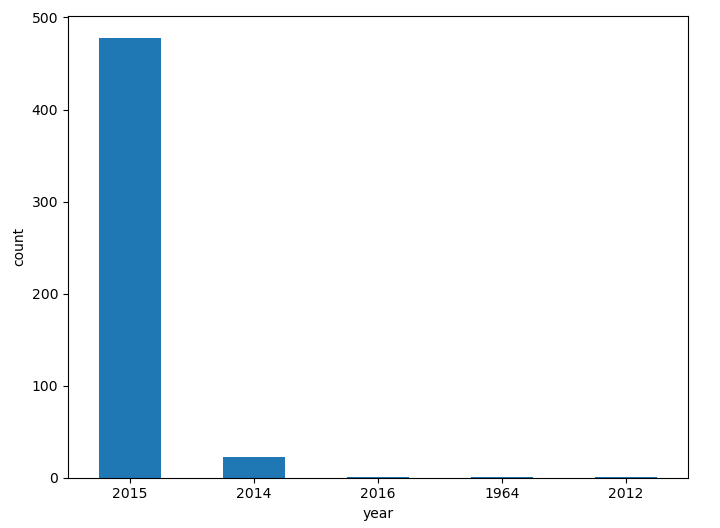
사진과 같이 2015년의 평가된 영화의 수가 압도적으로 많은 것을 확인 할 수 있습니다.
아마도 제 추측상 해당 데이터는 2016년 초반에 만들어진 데이터셋인 거 같습니다.(제 추측이지 확실한 것은 아닙니다!!)
이번에는 투표수가 제일 많은 영화 10개를 뽑아내는 작업을 해보겠습니다.
fandango.sort_values(by='VOTES', ascending=False).head(10)네 이런 식으로 VOTES를 기준으로 내림차순 정렬을 하게 되면 TOP10의 결과를 출력할 수 있습니다.
이번 작업은 투표수가 0인 영화의 개수를 출력해보겠습니다.
zero_vote = fandango[fandango['VOTES'] == 0]
len(zero_vote['FILM'].unique())해당 코드 결과 68개가 나왔습니다.
그렇다면 투표 수가 0인 영화들을 제거 한 후 데이터프레임을 만들면 데이터 행의 개수는 503 - 68 = 435개가 될 것입니다.
review_film = fandango.drop(fandango[fandango['FILM'].isin(zero_vote['FILM'])].index)
review_film.info()위의 코드 처럼 drop을 활용하여 위에서 만든 zero_vote의 FILM값이 원래 데이터 프레임인 fandango의 FILM에 있다면 해당하는 row를 삭제하는 작업입니다.
자료와 실습 도움을 준 강의입니다. (Udemy - Python for Machine Learning & Data Science Masterclass)
'Project > data analysis' 카테고리의 다른 글
| [zero-base] 스타벅스와 이디야 매장 거리 분석 (보충) (0) | 2024.10.23 |
|---|---|
| [zero-base] 스타벅스와 이디야 매장 거리 분석 (1) | 2024.10.22 |
| 데이터 분석 및 시각화하기 (영화 평점과 티켓 수익률) - Project 4 (4) | 2024.09.13 |
| 데이터 분석 및 시각화 하기 (영화 평점과 티켓 수익률) - Project 3 (1) | 2024.09.13 |
| 데이터 분석 및 시각화하기 (영화 평점과 티켓 수익률) - Project 1 (1) | 2024.09.12 |