이제 다른 영화 사이트인 MetaCritic의 평점을 간단히 산점도 분포표를 통해 살펴 보겠습니다.
fig = plt.figure(figsize=(10, 4),dpi=200)
sns.scatterplot(data=all_sites, x='Metacritic', y='Metacritic_User')
plt.xlim(0, 100)
plt.ylim(0,10)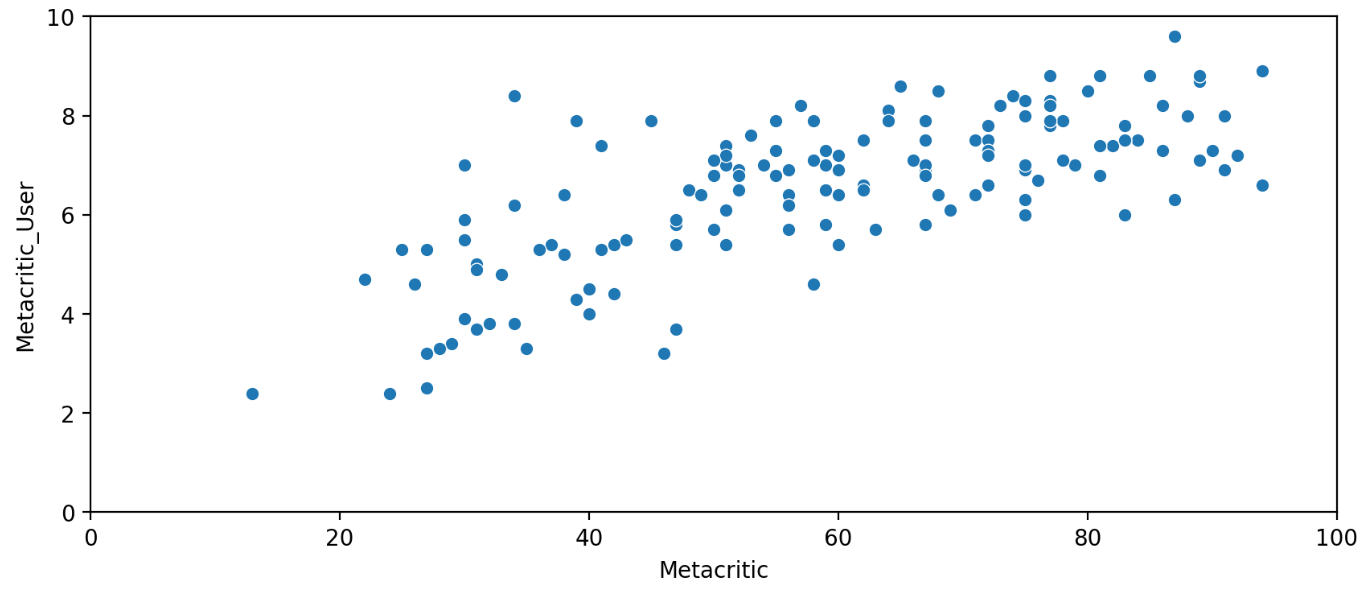
비평가 점수(Metacritic)와 사용자 점수( Metacritic_User) 간의 상관관계를 시각적으로 파악할 수 있습니다.
현재 분포도를 보면 평가가 골고루 분포 하는 것을 알 수 있습니다.
비평가의 점수는 작으나 사용자의 점수가 높은 것은 비평가에게는 안좋은 평이지만 사용자에게는 재미있었다는 영화일 수도 있다는 것을 알 수 있는 그래프입니다.
이번에는 마지막 영화 사이트인 IMDB의 투표 수와 Metacritic의 투표 수를 통해 가장 인기 있는 영화에 대해 알아 보겠습니다.
우선 산점도 그래프로 알아보겠습니다.
fig = plt.figure(figsize=(10, 6), dpi=200)
sns.scatterplot(data=all_sites, x='Metacritic_user_vote_count', y='IMDB_user_vote_count')
이상치에 해당하는 영화가 무엇인지에 대해 알아보겠습니다.
해당 영화를 구하기 위해서는 count의 수를 내림차순 정렬하여 맨 위에 있는 값을 가져오겠습니다.
# IMDB_user_vote_count에서 투표 수가 제일 많은 값
all_sites.sort_values(by='IMDB_user_vote_count', ascending=False).head(1)
# Metacritic_user_vote_count에서 투표 수가 제일 많은 값
all_sites.sort_values(by='Metacritic_user_vote_count', ascending=False).head(1)IMDB에서는 The Imitation Game (2014) 라는 영화의 투표 수가 가장 많았습니다.
Metacritic에서는 Mad Max: Fury Road (2015) 라는 영화의 투표 수가 가장 많았습니다.
Fandango 점수와 모든 사이트의 점수를 비교하여 Fandango가 인위적으로 높은 평점을 표시하여 티켓 판매를 촉진하는지 여부를 탐색해 보겠습니다.
우선, Fandango 테이블과 All Sites 테이블을 결합하겠습니다. 하지만 모든 Fandango 영화가 All Sites 테이블에 있는 것은 아니며, 일부 Fandango 영화는 리뷰가 거의 없거나 아예 없는 경우도 있습니다.
따라서 두 DataFrame 모두에 있는 영화만 비교하기 위해 FILM 열을 기준으로 두 DataFrame을 내부 병합(Inner Merge)하여 결합합니다.
all_site_film = pd.merge(review_film, all_sites, how='inner', on='FILM')
all_site_film.info()위의 코드와 같이 merge함수를 사용하고 how를 통해 inner merge를 이용하였으며 on을 통해 FILM을 기준으로 합친 것을 볼 수 있습니다.
이렇게 merge한 결과 모든 행은 145개로 나왔습니다.
Fandango의 0-5 별 범위에 맞추기 위해 모든 평점 데이터를 정규화합니다.
1. 여기서 다른 사이트들의 값들은 모두 100점 또는 10점을 기준으로 되어 있기 때문입니다.
2. 이 것을 모두 다같이 0~5의 범위로 바꿔줘야 합니다.
3. 그러기 위해서는 각 컬럼들의 최댓값을 보고 몇 점을 기준으로 되어있는지 확인 해야 합니다.
4. 그리고 100점은 100/5 의 값인 20으로 나눠주고 10점은 10/5의 값인 2로 나누어 주면 됩니다.
위의 절차를 통해 RT, Metacritic, IMDB 등에서의 평점 데이터를 Fandango와 일치하도록 변환합니다.
새로운 정규화된 평점 열을 생성하여 각 평점 시스템을 Fandango의 0-5 별 기준에 맞춥니다.
# RT사이트들의 평점 정규화
all_site_film['RT_Norm'] = np.round(all_site_film['RottenTomatoes']/20,1)
all_site_film['RTU_Norm'] = np.round(all_site_film['RottenTomatoes_User']/20,1)
# Meta사이트들의 평점 정규화
all_site_film['Meta_Norm'] = np.round(all_site_film['Metacritic']/20,1)
all_site_film['Meta_U_Norm'] = np.round(all_site_film['Metacritic_User']/2,1)
# IMDB사이트 들의 평점 정규화
all_site_film['IMDB_Norm'] = np.round(all_site_film['IMDB']/2,1)
all_site_film.head()

이제 정규화된 평점만 포함된 norm_scores DataFrame을 생성하겠습니다. 원래 Fandango 테이블에서 STARS와 RATING 두 열을 모두 포함해야 합니다.
columns = ['STARS','RATING','RT_Norm','RTU_Norm','Meta_Norm','Meta_U_Norm','IMDB_Norm']
df = all_site_film[columns]
df.head()
이제 진짜 순간이 왔습니다! Fandango가 비정상적으로 높은 평점을 표시하는지 확인해 보겠습니다. 우리는 이미 Fandango가 STARS보다 RATING을 더 높게 표시한다는 것을 알고 있지만, 실제 평점 자체가 평균보다 높은지 살펴보겠습니다.
모든 사이트에서 정규화된 평점 분포를 비교하는 플롯을 생성하겠습니다.
# legend 출력을 위한 함수 생성
def move_legend(ax, new_loc, **kws):
old_legend = ax.legend_
handles = old_legend.legendHandles
labels = [t.get_text() for t in old_legend.get_texts()]
title = old_legend.get_title().get_text()
ax.legend(handles, labels, loc=new_loc, title=title, **kws)
fig,ax = plt.subplots(figsize=(15, 6), dpi=200)
# kde그래프를 통해 data를 df로 하면 모든 컬럼들을 그래프에 출력할 수 있습니다.
sns.kdeplot(data=df, fill=True, clip=[0,5], palette='Set1')
move_legend(ax, "upper left")
위의 이미지를 보는 것과 같이 STARS와 RATING의 평점 평균이 다른 평점에 비해 높은 것을 확인하실 수 있습니다.
이 뜻은 Fandango의 평점이 티켓 매출을 올리기 위해 조작을 했을 수 있다느 것으로 추측이 가능합니다.
그리고 녹색 그래프(RT_Norm)를 보면 가장 균일한 분포를 가진 것을 보실 수 있습니다.
이번에는 RT 비평가의 분포가 가장 균일하다는 것을 알 수 있습니다. 이 두 분포를 직접 비교해 보겠습니다.
fig,ax = plt.subplots(figsize=(15, 6), dpi=200)
sns.kdeplot(data=df[['RT_Norm', 'STARS']], fill=True, clip=[0,5])
move_legend(ax,'upper left')
확실히 STARS 그래프의 값은 2.5 미만 정도의 평점은 없으며, 과도하게 높은 평점들만 있는 것을 확인 할 수 있습니다.
이번에는 다른 그래프로 정규화된 평점을 시각화해보겠습니다.(clustermap)
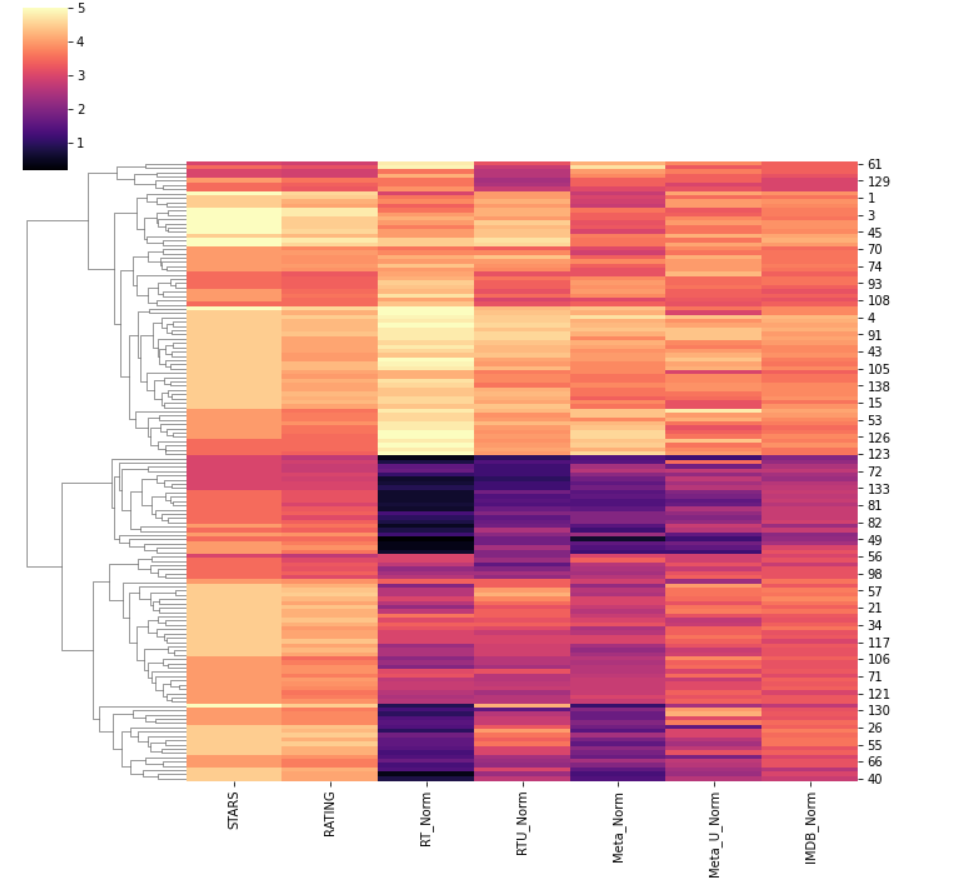
Fandango가 다른 사이트들보다 영화를 훨씬 더 높은 점수로 평가하고 있으며, 평점을 반올림하여 표시하고 있다는 것이 명확합니다.
이제 상위 10개의 최악의 영화를 살펴보겠습니다. Rotten Tomatoes 비평가 평점을 기준으로 상위 10개의 최저 평점을 받은 영화를 확인해보겠습니다.
# 결과를 보기 위해서 정규화된 평점 DataFrame에 FILM 열을 다시 추가하였습니다.
norm_film=all_site_film[['STARS', 'RATING', 'RT_Norm', 'RTU_Norm', 'Meta_Norm', 'Meta_U_Norm', 'IMDB_Norm', 'FILM']]
# Rotten Tomatoes 비평가 평점을 기준으로 상위 10개의 최저 평점 영화 확인
worst_movie = norm_film.sort_values(by='RT_Norm').head(10)
최종 작업으로 상위 10개의 최악의 영화에 대한 모든 사이트에서의 평점 분포를 시각화해보겠습니다.

이제 최종적으로 분석 결과를 말해보자면 명백히 평가가 나쁜 영화에 대해 약 3-4 별의 평점을 보여주고 있습니다.
즉, Fandango의 영화 사이트는 평점을 높게 측정시켜 사람들이 영화 티켓을 구매하도록 유도한 것을 확인 할 수 있었습니다.
그 중 가장 큰 문제를 일으킨 영화는 Taken 3입니다! Fandango는 이 영화에 대해 평균 1.86인 평점에 비해 사이트에서 4.5 별을 표시하고 있습니다.
- 영화사이트들의 Taken 3 평점 평균 구하는 식 : (0.4 + 2.3 + 1.3 + 2.3 + 3) / 5 = 1.38
네!! 이상으로 해당 프로젝트는 여기까지 하겠습니다.
다음 프로젝트는 OTT 관련으로 제가 직접 공공데이터를 수집하여 분석해보는 경험을 해보겠습니다!
이상입니다.
자료와 실습 도움을 준 강의입니다. (Udemy - Python for Machine Learning & Data Science Masterclass)
'Project > data analysis' 카테고리의 다른 글
| [zero-base] 스타벅스와 이디야 매장 거리 분석 (보충) (0) | 2024.10.23 |
|---|---|
| [zero-base] 스타벅스와 이디야 매장 거리 분석 (1) | 2024.10.22 |
| 데이터 분석 및 시각화 하기 (영화 평점과 티켓 수익률) - Project 3 (1) | 2024.09.13 |
| 데이터 분석 및 시각화하기 (영화 평점과 티켓 수익률) - Project 2 (0) | 2024.09.12 |
| 데이터 분석 및 시각화하기 (영화 평점과 티켓 수익률) - Project 1 (1) | 2024.09.12 |