기사에서 언급된 바와 같이, HTML과 별점 표시 때문에 실제 사용자 평점은 사용자에게 표시된 평점과 약간 다를 수 있습니다. 이 차이를 시각화해보겠습니다.
표시된 평점(STARS)과 실제 평점(RATING)의 분포를 보여주는 KDE(커널 밀도 추정) 플롯을 생성합니다.
KDE를 0-5로 클리핑하겠습니다.
fig = plt.figure(figsize=(10.5, 4))
# label : legend에 표시할 이름 즉, 라벨이다.
# clip : 클리핑할 단위를 적는 것입니다.
sns.kdeplot(review_film, x='RATING',clip=[0,5], fill=True, label='True Rating')
sns.kdeplot(review_film, x='STARS',clip=[0,5], fill=True, label='Stars Displayed')
plt.legend(loc=(1.05, 0.5))
위의 사진 처럼 표시된 평점의 값이 실제 평점보다 높은 점수인 것을 확인 하실 수 있습니다.(x축의 5점을 확인하심 됩니다.)
이제 실제로 이 불일치를 정량화합시다.
표시된 평점(STARS)과 실제 평점(RATING) 간의 차이를 나타내는 새로운 열을 생성합니다. 이 차이는 STARS - RATING으로 계산하고, 이 차이 값을 소수점 첫째 자리까지 반올림합니다.
-> 정량화 하는 이유는 문제를 명확히 이해하고, 이를 해결하기 위한 구체적인 전략을 마련하는 데 도움이 되기 때문입니다.
review_film['STARS_DIFF'] = (review_film['STARS'] - review_film['RATING']).round(1)
review_film
이번에는 특정차이가 발생하는 횟수를 그래프로 표현해 보겠습니다.
fig = plt.figure(figsize=(12, 6))
counts = review_film['STARS_DIFF'].value_counts()
# colors : 그래프에 색상 입히기
colors = plt.cm.Purples(np.linspace(0.4, 1, counts.shape[0]))
sns.countplot(data=review_film, x='STARS_DIFF', palette=colors)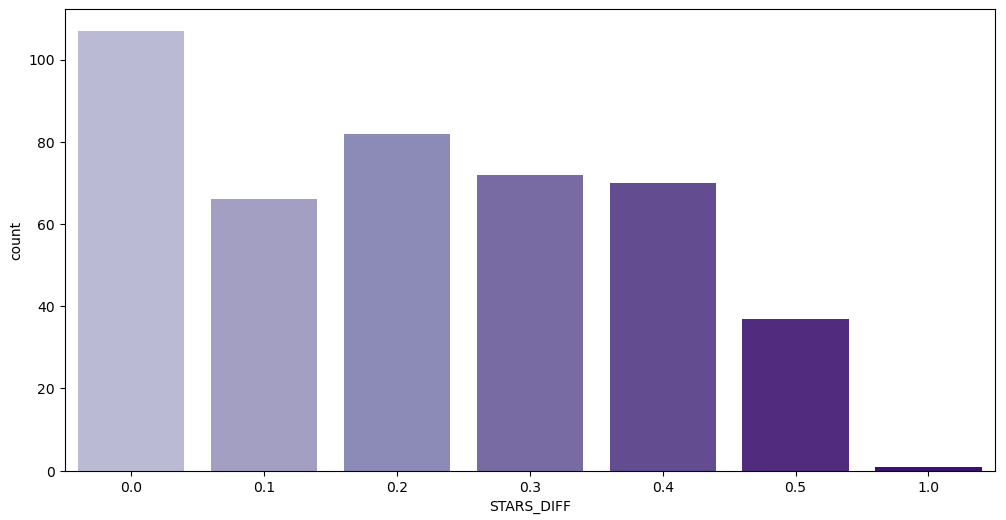
보아하니 표기된 평점과 실제 평점 차이의 결과가 1.0이 있는 것을 확인 할 수 있습니다.
해당하는 값의 영화가 무엇인지 알아보도록 하겠습니다.
review_film[review_film['STARS_DIFF'] == 1]
확인 결과 VOTES컬럼을 확인하니 2개로 매우 적은 수의 투표수를 가지고 있어 평점 차이가 커 보일 수 있으며, 이로 인해 평점이 실제 사용자 경험과 크게 다를 수 있습니다.
이번에는 Fandango의 점수를 다른 영화 사이트들과 비교해보겠습니다.
우선 "all_sites_scores.csv" 파일을 읽어 오겠습니다.
읽고 데이터 프레임에서 확인 해본 결과 각 영화 사이트에서의 점수와 투표 수가 입력되어있는 것을 확인 할 수 있었습니다.
이번에는 Rotten Tomatoes를 살펴봅시다. RT에는 두 가지 리뷰 세트가 있습니다. 하나는 공식 비평가들이 게시한 비평가 리뷰(RottenTomatoes)이고, 다른 하나는 사용자 리뷰(RottenTomatoes_User)입니다.
그리고 RT 비평가 리뷰와 RT 사용자 리뷰 간의 관계를 탐색하는 산점도를 생성하겠습니다.
import seaborn as sns
import matplotlib.pyplot as plt
# 그래프 크기 설정
fig = plt.figure(figsize=(10, 4))
# Scatterplot 그리기
sns.scatterplot(data=all_sites, x='RottenTomatoes', y='RottenTomatoes_User')
# x축과 y축 범위 설정
plt.xlim(0, 100)
plt.ylim(0, 100)
# 그래프 표시
plt.show()
해당 분포도를 보면 비평가 점수와 사용자 점수 간의 상관관계를 시각적으로 파악할 수 있습니다.
현재 분포도를 보면 비평가와 사용자 모두 100에 근접해있는 데이터가 많은 것으로 보아 특정영화에 대해 매우 높은 점수를 부여 했다는 것을 알 수 있으며,
비평가의 점수는 작으나 사용자의 점수가 높은 것은 비평가에게는 안좋은 평이지만 사용자에게는 재미있었다는 영화일 수도 있다는 것을 알 수 있는 그래프인 거 같습니다.
이제 비평가 평점과 RT 사용자 평점을 비교하여 그 차이를 정량화해보겠습니다.
RottenTomatoes - RottenTomatoes_User로 이 차이를 계산할 것입니다. 여기서 Rotten_Diff는 비평가 점수와 사용자 점수의 차이입니다.
값이 0에 가까울수록 비평가와 사용자의 의견이 일치한다는 것을 의미합니다. 값이 양수로 클수록 비평가가 사용자보다 훨씬 높게 평가한 것이고, 음수로 클수록 사용자가 비평가보다 훨씬 높게 평가한 것입니다.
all_sites['Rotten_Diff'] = all_sites['RottenTomatoes'] - all_sites['RottenTomatoes_User']이렇게 간단하게 '-'를 사용하면 모든 행에 적용이 되게 됩니다.
이제 전체 평균 차이를 비교해 봅시다. 우리는 음수 또는 양수일 수 있는 차이를 다루고 있으므로, 먼저 모든 차이의 절대값을 구한 다음, 그 평균을 계산해야 합니다.
이렇게 하면 비평가 평점과 사용자 평점 간의 평균 절대 차이를 확인할 수 있습니다
평균 절대 차이를 구하는 이유는??
-> 평가 차이가 어느 방향으로 크든지 그 크기를 정확히 측정할 수 있습니다. 이를 통해 비평가 평점과 사용자 평점 간에 실제 차이의 크기를 파악할 수 있습니다.
abs_rotten_diff = abs(all_sites['RottenTomatoes'] - all_sites['RottenTomatoes_User'])
abs_rotten_diff.mean()abs를 이용하여 평균 절대 차이를 확인 할 수 있었습니다.
결과는 약 15.1이 나왔습니다. 이 뜻은 비평가 평점과 사용자 평점 간에 평균적으로 약 15점의 차이가 있다는 것을 의미합니다.
즉, 15점 차이라는 것은 중간 정도의 편차로 볼 수 있으며, 비평가와 사용자 간의 평가 기준이나 영화에 대한 관점이 어느 정도 다를 수 있음을 의미합니다.
이번에는 분포그래프를 통해 RT 비평가 점수와 RT 사용자 점수 간의 차이를 시각적으로 확인해보겠습니다.
이 분포에는 음수 값이 포함되어야 합니다. 분포를 표시하기 위해 KDE(커널 밀도 추정)나 히스토그램을 자유롭게 사용할 수 있습니다.
fig = plt.figure(figsize=(10, 4),dpi=200)
sns.histplot(data=all_sites , x='Rotten_Diff', kde=True, bins=25)
plt.title('RT Critics Score minus RT User Score')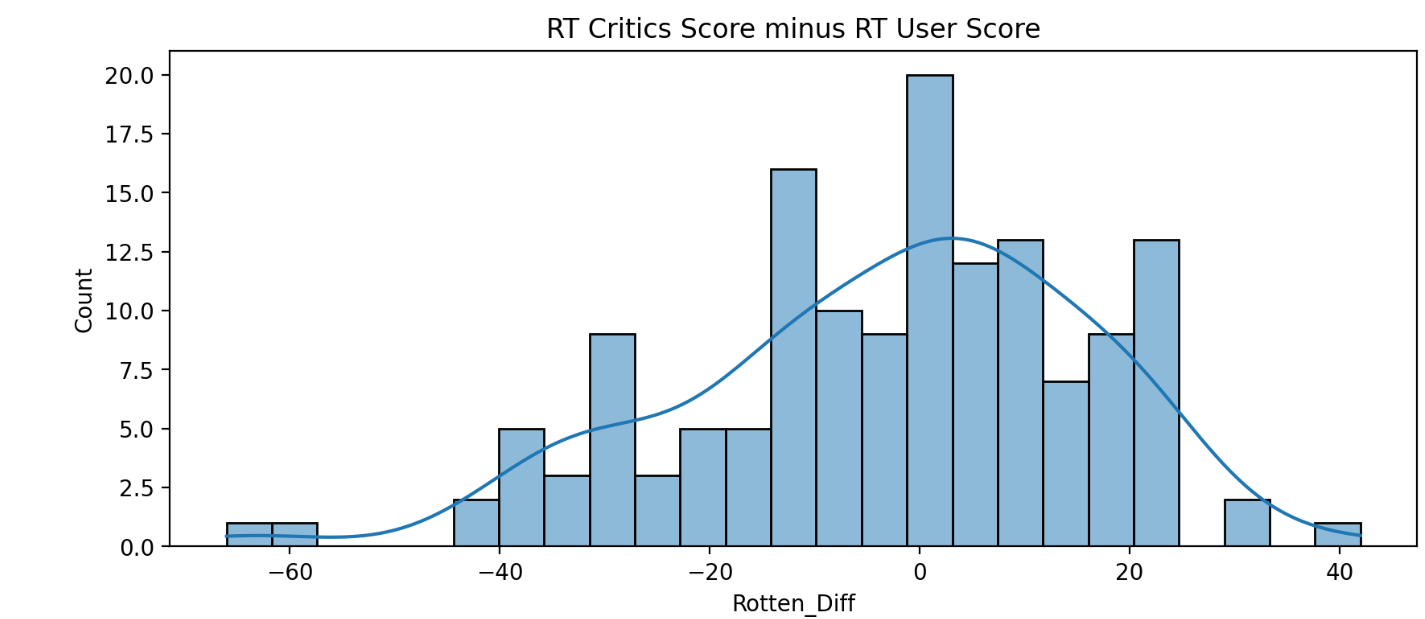
위 사진의 결과 비평가 점수와 사용자 점수의 차이가 극명하게 차이나는 경우는 조금 확인이 되지만 대체로 0점 주위에 분포하는 것으로 보아 Rotten Tomatoes사이트는 비평가 점수와 사용자 점수 간의 차이가 작다는 것을 의미합니다.
이제 Rotten Tomatoes에서 비평가와 사용자 간의 절대값 차이를 이용하여 그래프를 그려 좀 더 명확하게 확인 해보겠습니다.
fig = plt.figure(figsize=(10, 4),dpi=200)
sns.histplot(data=abs_rotten_diff, bins=25, kde=True)
plt.title('Abs Difference between RT Critics Score and RT User Score')
plt.show()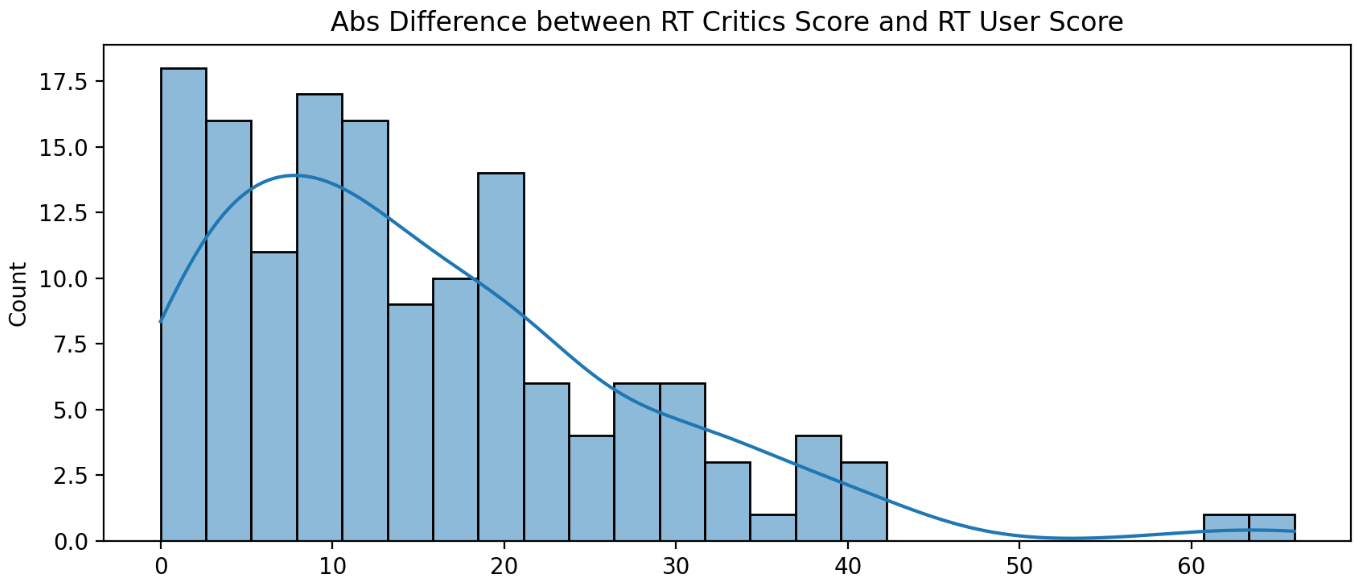
위의 사진을 보아 0점 주위 분포하는 것이 매우 많은 것으로 확인되어 비평가와 사용자 간의 점수 차이가 조금은 있으나 극명하게 차이나지는 않는 것으로 확인 되어 신뢰할 수 있는 사이트로 보아도 될 거 같습니다.(제 추측입니다.)
가장 큰 차이를 초래하는 영화들을 알아봅시다. 먼저, 사용자와 RT 비평가 간의 가장 큰 음수 차이를 보이는 상위 5개 영화를 출력해보겠습니다.
# 유저는 재밌게 봤으나 평론가들의 평은 최악
all_sites[['FILM','Rotten_Diff']].sort_values(by='Rotten_Diff').head()
# 평론가는 높게 평가하였으나 시청자들은 최악의 평가
columns = ['FILM','Rotten_Diff']
all_sites[columns].sort_values(by='Rotten_Diff', ascending=False).head()
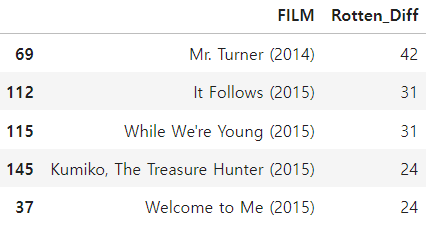
이렇게 출력을 할 수 있었고 해당 영화들에대해 조사를 해보면 이제 왜 이런 결과가 나왔는지 알 수 있을 것입니다.
느낀점: 이번에 코딩을 해보며 왜 절대평균차이를 구하는지 왜 유저 평가 점수와 평론가 평가 점수로 분포 그래프를 나타내는지 정확하게 알지 못하였으나,
정량화 하는 이유에 대해 알고나서 왜 하는지 알 수 있었던 것 같습니다. 우선 정량화를 통해 해당 실제 점수와의 차이를 통해 무엇이 진실인지 이 데이터가 무엇을 의미하는지에 대해 알수 있었습니다.
ex) 값이 0에 가까울수록 비평가와 사용자의 의견이 일치한다는 것을 의미하고 값이 양수로 클수록 비평가가 사용자보다 훨씬 높게 평가한 것이고, 음수로 클수록 사용자가 비평가보다 훨씬 높게 평가하는 것을 알 수 있었습니다.
해당 값들의 절댓값으로 평균을 해보면 차이가 어느 정도 차이나는지 알 수 있고 해당 평균으로 이 그래프가 정확한평가도 이루어진 것인지도 알 수 있다는 것도 알 수 있었습니다.
이상입니다.
'Project > data analysis' 카테고리의 다른 글
| [zero-base] 스타벅스와 이디야 매장 거리 분석 (보충) (0) | 2024.10.23 |
|---|---|
| [zero-base] 스타벅스와 이디야 매장 거리 분석 (1) | 2024.10.22 |
| 데이터 분석 및 시각화하기 (영화 평점과 티켓 수익률) - Project 4 (4) | 2024.09.13 |
| 데이터 분석 및 시각화하기 (영화 평점과 티켓 수익률) - Project 2 (0) | 2024.09.12 |
| 데이터 분석 및 시각화하기 (영화 평점과 티켓 수익률) - Project 1 (1) | 2024.09.12 |