우선 해당 주제를 가져온 이유는 이디야커피는 가끔 스타벅스 매장이 위치한 곳에 매장을 위치하는 것이 아니냐는 의심을 받곤 합니다. 그리고 공식적으로 이디야 커피 회장은 이 사실을 부인 한 것으로 알고 있습니다.
그래서 직접 이디야 매장 위치와 스타벅스 위치 데이터들을 가져와서 분석해보고 사실인지 아닌지를 판단 해보겠습니다.
문제 1 : 서울시 스타벅스 매장 위치 크롤링
from selenium import webdriver
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
import time
star_url = "https://www.starbucks.co.kr/store/store_map.do"
driver = webdriver.Chrome()
url = star_url
driver.get(url)
driver.maximize_window()
local_search = driver.find_elements(By.CLASS_NAME, 'loca_search')
local_search[0].click()
# 전체 클릭
gu_select = driver.find_elements(By.CLASS_NAME, 'set_gugun_cd_btn')[0].click()
driver.find_elements(By.CLASS_NAME, 'quickSearchResultBoxSidoGugun')[0].click()
# 서울 전체 매장 위치 목록들
SearchResultBox = driver.find_elements(By.CLASS_NAME, 'quickResultLstCon')
# 페이지 가져오기
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
locations = soup.find_all('li', class_='quickResultLstCon')
# 리스트에 매장 이름, 위치(lat, lnt) -> 나중에 사용할 것 같아서 넣음.
# 상세 주소
names_star = [] # 매장 이름
lat_star = [] # 매장 lat
lng_star = [] # 매장 long
address_star = [] # 매장 상세 주소
for loc in locations:
addr = loc.find('p', class_='result_details').text
# 기본 값으로 '대전'지역도 포함되어있어서 서울만 뽑도록 설정
if '서울' in addr:
names_star.append(loc.get('data-name'))
lat_star.append(loc.get('data-lat'))
lng_star.append(loc.get('data-long'))
address_star.append(addr)
# 구 이름 빼놓기
gu_star = []
for addr in address_star:
gu_star.append(addr.split(' ')[1])
# data Frame으로 변환
import pandas as pd
starbucks = pd.DataFrame(names_star, columns=['매장 이름'])
starbucks['지역구'] = gu_star
starbucks['상세주소'] = address_star
starbucks['경도'] = lng_star
starbucks['위도'] = lat_star우선 스타벅스 공식 홈페이지에서 서울 시 매장 별 위치를 크롤링을 했습니다.
크롤링할 때 각각의 값을 리스트에 추가하는 방식으로 했구요!
그리고 지역구는 원래 주소 값에서 split() 함수 사용 후 1번째 배열에 있는 값을 가져와서 넣어놓았습니다.

깔끔하게 데이터들이 모두 들어온 것을 확인 할 수 있습니다!!
문제 2 : 서울시 이디야 매장 위치 크롤링
ediya_url = 'https://www.ediya.com/contents/find_store.html'
driver = webdriver.Chrome()
url = ediya_url
driver.get(url)
driver.maximize_window()
driver.find_elements(By.LINK_TEXT, "주 소")[0].click()
search_box = driver.find_elements(By.CLASS_NAME, "sch_txt")
from selenium.webdriver.common.keys import Keys
lat_ediya = []
lng_ediya = []
name_ediya = []
address_ediya = []
# 스타벅스에서 나온 지역구를 토대로 검색
for gu in starbucks['지역구'].unique():
search_box[1].clear() # 해당 칸에 글씨 있을 경우 삭제
search_box[1].click() # 검색창 클릭
search_box[1].send_keys("서울 " + gu) # 지역구 넣기
search_box[1].send_keys(Keys.RETURN) # 엔터
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
locations = soup.find_all('li', class_='item')
# 매장 이름, 주소 가져오기
for loc in locations:
name_ediya.append(loc.find('dt').text)
address_ediya.append(loc.find('dd').text)
onclick_value = loc.find('a').get('onclick')
if 'panLatTo' in onclick_value:
lat_lng = onclick_value.split('(')[1].split(')')[0]
lng_ediya.append(lat_lng.split(',')[0].strip("'"))
lat_ediya.append(lat_lng.split(',')[1].strip("'"))
# 경도, 위도 없을 경우 0으로 넣기
else :
lng_ediya.append(0)
lat_ediya.append(0)
# 구 이름 빼놓기
gu_ediya = []
for addr in address_ediya:
gu_ediya.append(addr.split(' ')[1])
ediya = pd.DataFrame(name_ediya, columns=['매장 이름'])
ediya['지역구'] = gu_ediya
ediya['상세주소'] = address_ediya
ediya['경도'] = lng_ediya
ediya['위도'] = lat_ediya
ediya이디야 매장 또한 서울시를 중점으로 두고 크롤링 하였습니다.
위의 스타벅스에서 했던 것처럼 리스트에 저장하고 해당 값들을 데이터프레임에 넣어주었습니다.

문제 발생!!
하지만 문제가 있었습니다. 이디야 매장은 위도와 경도 값이 입력이 안된 것이 매우 많았습니다. 그래서 우선 0으로 채워 넣어 놓았습니다.
해결방법
크롤링 해온 데이터에 있는 상세 주소를 가져와 위도 경도 찾을 수 있는 사이트에 검색을 한 다음 크롤링하면 될 것 같습니다.(해당 내용은 다음 글에서 적용해보겠습니다.)
문제 3 : 이디야 커피는 스타벅스 커피 매장 근처에 있는지 분석하기
1. 첫 번째로 이디야 매장에서 수집되지 않은 경도 위도 값들을 결측치로 판단하고 모두 제거해주었습니다.
ediya = ediya[(ediya['경도'] != 0) & (ediya['위도'] != 0)]2. 매장 별 위치를 좀 더 눈으로 보기 위해 folium을 사용해보았습니다.
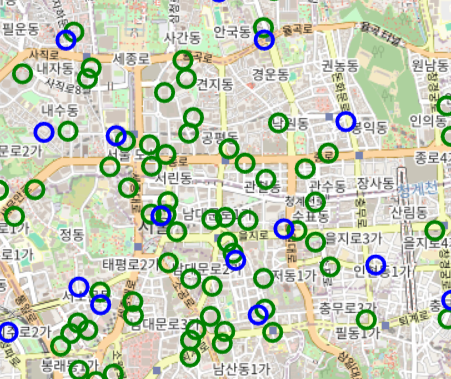
이렇게 보듯이 스타벅스는 초록색 이디야는 파란색입니다. 이렇게 보면이디야 매장이 꼭 스타벅스 근처에 있는 것 처럼 보입니다. 하지만, 스타벅스 매장이 이디야 매장보다 거의 400개 정도 차이가 났습니다.
그래서 지도를 통해 확인하는 것은 불확실하다 판단하였습니다.
그리고 또 확대를 하여 확인을 해보면 좀 거리가 있는 곳에 위치한 것 같기도 하고 아닌 것 같은 경우가 매우 많이 보였습니다.
3. 너무 애매하여 구마다 스타벅스와 이디야의 거리 평균을 구해보았습니다.
우선 거리 평균을 구하기 위하여 geodesic을 사용하여 해결해 보았습니다.
from geopy.distance import geodesic
average_distances_dict = {}
for gu in starbucks['지역구'].unique():
distances = []
for _, star_row in starbucks[starbucks['지역구'] == gu].iterrows():
star_loc = (star_row['위도'], star_row['경도'])
for _, ediya_row in ediya[ediya['지역구'] == gu].iterrows():
ediya_loc = (ediya_row['위도'], ediya_row['경도'])
# 두 매장간 거리 (km로 계산)
distance = geodesic(star_loc, ediya_loc).kilometers
distances.append(distance)
average_distance = sum(distances) / len(distances)
average_distances_dict[gu] = average_distance
average_distances_dict
이렇게 구마다 거리 평균을 구해본 결과 구마다 평균 거리가 약 2km(도보 25분)인 것을 확인 할 수 있었습니다.
그래서 제 분석으로는 이디야 매장은 스타벅스 매장 주변에 위치하지 않는 것으로 판단하였습니다!
다음 글에서는 0으로 된 위도와 경도의 값을 모두 찾고 다시 분석을 해보겠습니다.
이 글은 제로베이스 데이터 분석 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.
이상입니다.
'Project > data analysis' 카테고리의 다른 글
| [zero-base] 셀프 주유소는 정말로 저렴한가? (1) | 2024.10.25 |
|---|---|
| [zero-base] 스타벅스와 이디야 매장 거리 분석 (보충) (0) | 2024.10.23 |
| 데이터 분석 및 시각화하기 (영화 평점과 티켓 수익률) - Project 4 (4) | 2024.09.13 |
| 데이터 분석 및 시각화 하기 (영화 평점과 티켓 수익률) - Project 3 (1) | 2024.09.13 |
| 데이터 분석 및 시각화하기 (영화 평점과 티켓 수익률) - Project 2 (0) | 2024.09.12 |