해당 주제는 실제로 셀프 주유소가 기름값이 더 저렴한지 궁금하여 선택한 주제 입니다. 그래서 직접 주유소 홈페이지를 들어가서 크롤링 후 실제로 더 저렴한지 분석해보겠습니다.
1. 서울시 각 구별 주유소 데이터 크롤링
from selenium import webdriver
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
from selenium.webdriver.support.select import Select
import time
# 대한민국 주유 가격 알아보는 사이트
url = 'https://www.opinet.co.kr/searRgSelect.do'
# 창 열기
driver = webdriver.Chrome()
driver.get(url)
driver.maximize_window()
# 서울 선택
select_Seoul = Select(driver.find_element(By.NAME, 'SIDO_NM0'))
select_Seoul.select_by_index(1)
# 구 선택
name = [] # 주유소 이름
address = [] # 주소
brand = [] # 상호명
gasoline_price = [] # 휘발유 가격
diesel_price = [] # 경유 가격
self = [] # 셀프 주유소 유무
car_wash = [] # 세차장 유무
charging_station = [] # 충전소 유무
maintenance = [] # 경정비 유무
convenience_store = [] # 편의점 유무
hour_24 = [] # 24시간 유무
gu = [] # 구
lat = [] # 위도
lng = [] # 경도
for i in range(1, 26):
select_gu = Select(driver.find_element(By.NAME, 'SIGUNGU_NM0'))
select_gu.select_by_index(i)
time.sleep(3) # sleep 안할 시 로딩 중 클릭으로 오류 발생
# 조회 누르기
click_search = driver.find_elements(By.CLASS_NAME, 'btn_type1')
click_search[0].click()
time.sleep(3) # sleep 안할 시 로딩 중 클릭으로 오류 발생
# 보통 휘발유 목록 전체
info_list = driver.find_elements(By.ID, 'body1')
click_gas_station = info_list[0].find_elements(By.CSS_SELECTOR,' a[href^="javascript:fn_osPop"]')
# 보통 휘발유 or 경유 목록 클릭하기
for i in range(len(click_gas_station)):
click_gas_station[i].click()
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
# 가져와야할 데이터 크롤링
name.append(soup.find('label', {'id': 'os_nm'}).text.strip())
address.append(soup.find('label', {'id': 'rd_addr'}).text.strip())
brand.append(soup.find('label', {'id': 'poll_div_nm'}).text.strip())
gasoline_price.append(int(soup.find('label', {'id': 'b027_p'}).text.strip().replace(",", "")))
diesel_price.append(int(soup.find('label', {'id': 'd047_p'}).text.strip().replace(",", "")))
self_TF = bool(soup.find('img', {'alt': '셀프주유소'}))
if self_TF:
self.append('Y')
else:
self.append('N')
car_wash_TF = 'off' in str(soup.find('img', {'id': 'cwsh_yn'}))
if car_wash_TF:
car_wash.append('N')
else :
car_wash.append('Y')
charging_station_TF = 'off' in str(soup.find('img', {'id': 'lpg_yn'}))
if charging_station_TF:
charging_station.append('N')
else :
charging_station.append('Y')
maintenance_TF = 'off' in str(soup.find('img', {'id': 'maint_yn'}))
if maintenance_TF:
maintenance.append('N')
else :
maintenance.append('Y')
convenience_store_TF = 'off' in str(soup.find('img', {'id': 'cvs_yn'}))
if convenience_store_TF:
convenience_store.append('N')
else :
convenience_store.append('Y')
hour_24_TF = 'off' in str(soup.find('img', {'id': 'sel24_yn'}))
if hour_24_TF:
hour_24.append('N')
else :
hour_24.append('Y')
gu.append(address[0].split(' ')[1])
driver.quit()
import pandas as pd
df = pd.DataFrame({
'name': name,
'address': address,
'brand': brand,
'gasoline_price': gasoline_price,
'diesel_price': diesel_price,
'self': self,
'car_wash': car_wash,
'charging_station': charging_station,
'maintenance': maintenance,
'convenience_store': convenience_store,
'hour_24': hour_24,
'gu': gu
})
df저는 리스트에 각각의 값들을 모두 저장하는 바람에 코드가 매우 길어졌으나 꼭 크롤링을 저처럼 하시지 않아도 됩니다.
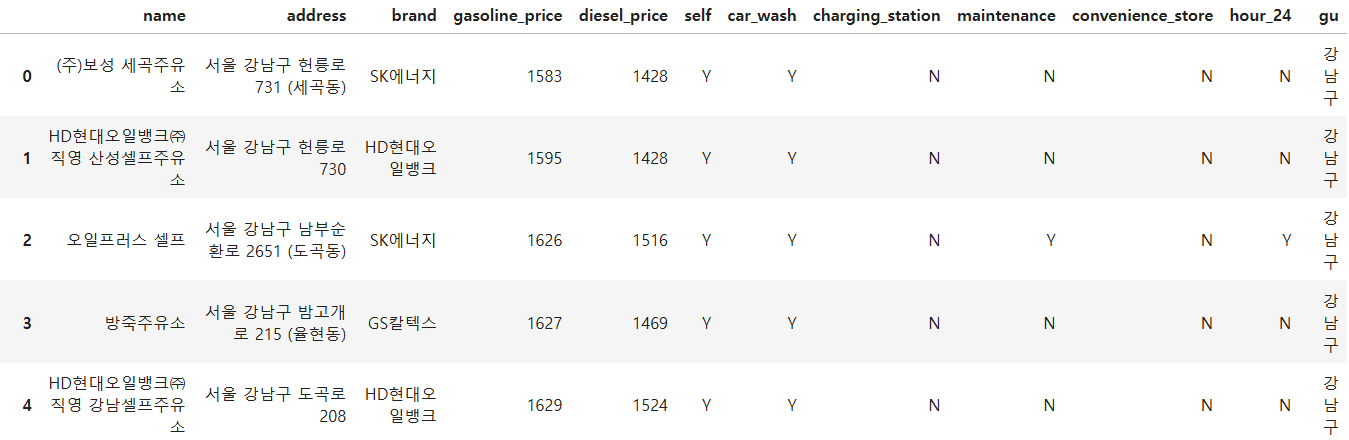
코드는 매우 길지만 저희가 원하는 결과를 딱 가져온 것을 확인 할 수 있었습니다.
2. 주유소에 추가되어있는 운영 여부에 따른 상관성 분석
df.drop(columns=['name','address', 'brand','gu'], axis=1)
.replace({'Y': 1, 'N': 0}).corr()
셀프 주유수 여부에서 그나마 약한 상관관계를 보입니다.
하지만 저는 피어슨 상관계수(corr)를 사용하였으나, 매우 큰 실수 였었습니다. 왜냐하면 범주형 변수(Y/N이 들어있는 변수)를 피어슨 상관계수를 사용하여 분석하는데에는 한계가 있기 때문입니다.
해결방법!!
- 포인트 바이세리얼 상관계수 계산
연속형 변수와 이진형 범주 변수를 각각 나눠서 포인트 바이세리얼 상관계수를 계산할 수 있습니다. - 각 이진 변수와 연속 변수 간의 t-검정
각 이진 변수(Y/N 변환 값)와 연속 변수 간의 차이가 유의미한지 확인하는 t-검정을 사용할 수 있습니다. 예를 들어, 기름값을 두 그룹(Y와 N)에 나눠 평균 차이가 있는지를 분석하여 상관성을 확인합니다. - 로지스틱 회귀 분석
기름값의 상하위 구간을 기준으로 이진 종속 변수를 만들어, 각 변수의 기여도를 로지스틱 회귀로 확인하는 방법도 좋습니다.
해당 문제는 다음 글에서 해결해보겠습니다.
3. Self 주유소와 아닌 주유소의 휘발유 가격 대조
df.groupby('self')[['gasoline_price', 'diesel_price']].agg(['max', 'mean'])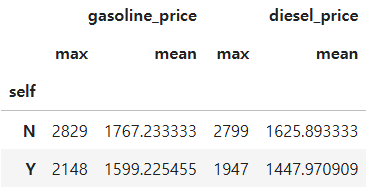
휘발유 가격과 경유 가격에서 제일 큰 값으로 비교해본 결과 셀프 주유소가 아닌 곳의 가격이 매우 큰 것으로 확인되었습니다. 그리고 가격 평균으로 확인 해본 결과 셀프 주유소가 약 160원 정도 저렴한 것으로 확인 되었습니다.
하지만 셀프 주유소가 아닌 곳의 outlier를 확인하여 이로 인한 평균 증가인 것인지 박스 플롯을 통해 확인 해보겠습니다.
4. 박스플롯 생성 및 Outlier 제거
import seaborn as sns
import matplotlib.pyplot as plt
plt.subplot(211)
sns.boxplot(data=df, y=df['self'], x=df['gasoline_price'], hue=df['self']);
plt.subplot(212)
sns.boxplot(data=df, y=df['self'], x=df['diesel_price'], hue=df['self']);
plt.tight_layout()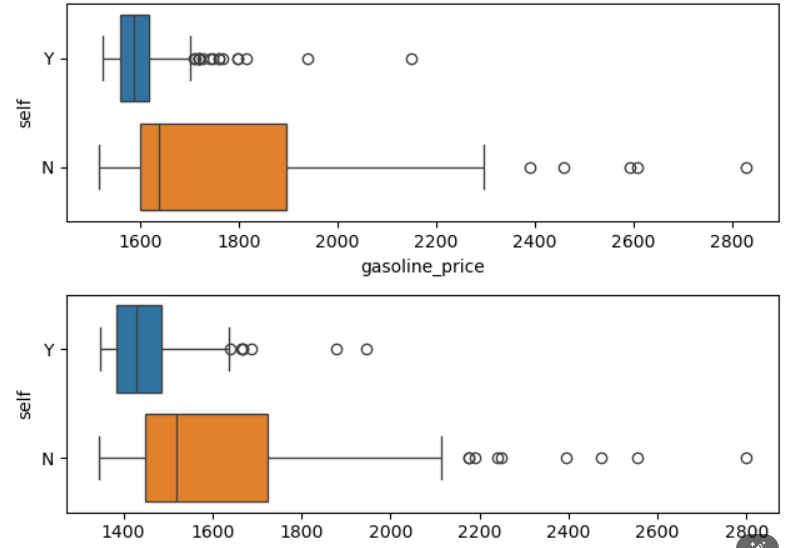
Boxplot으로 확인 해본 결과 두 개의 그래프 모두 Outlier가 좀 보이며(특히 셀프 주유소가 아닌 곳은 말도 안되게 비쌉니다...) 셀프 주유소가 아닌 곳 들은 대체로 셀프 주유소보다 높은 가격대에 분포하는 것으로 보입니다.
셀프 주유소에서의 outlier도 확실히 이상하긴 합니다. 평균이 1600원 정도인데 약 600원 차이도 보이기도 하구요..!!
Q1 = df[['gasoline_price', 'diesel_price']].quantile(q=0.25) # q1 값
Q3 = df[['gasoline_price', 'diesel_price']].quantile(q=0.75) # q3 값
IQR = Q3 - Q1
# 가솔린 이상치 제거 후 DataFrame
gasoline_outlier_del_df = df[(df['gasoline_price'] > Q1['gasoline_price'] - 1.5 * IQR['gasoline_price']) & (df['gasoline_price'] < Q3['gasoline_price'] + 1.5 * IQR['gasoline_price'])]
# 경유 이상치 제거 후 DataFrame
diesel_outlier_del_df = df[(df['diesel_price'] > Q1['diesel_price'] - 1.5 * IQR['diesel_price']) & (df['diesel_price'] < Q3['diesel_price'] + 1.5 * IQR['diesel_price'])]IQR을 활용하여 이상치를 제거하였습니다.
5. 가격 비교와 박스플롯으로 다시 확인하기
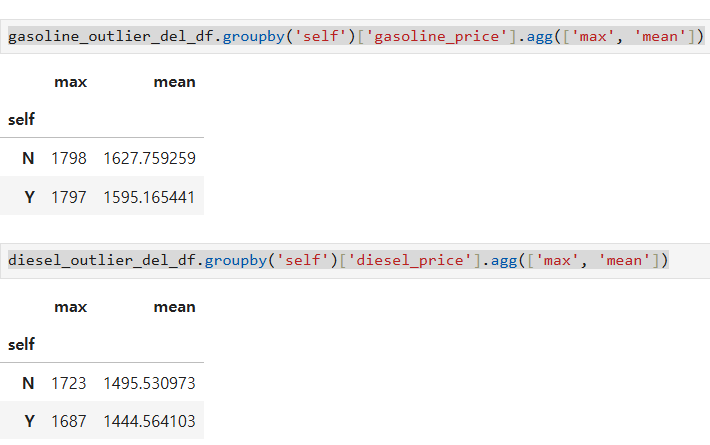
그래도 전 보다는 확실히 평균과 max값이 좀 더 안정된 것으로 확인 됩니다.
그리고 가솔린의 최대값은 거의 차이가 나지 않지만 평균 가격은 약 25원 정도의 차이가 있어 보입니다.
경유의 최대값 또한 거의 차이가 없으며 평균 가격은 약 50원 정도의 차이가 있습니다.
plt.subplot(211)
sns.boxplot(data=gasoline_outlier_del_df,
y=gasoline_outlier_del_df['self'],
x=gasoline_outlier_del_df['gasoline_price'],
hue=gasoline_outlier_del_df['self']);
plt.subplot(212)
sns.boxplot(data=diesel_outlier_del_df,
y=diesel_outlier_del_df['self'],
x=diesel_outlier_del_df['diesel_price'],
hue=diesel_outlier_del_df['self']);
plt.tight_layout()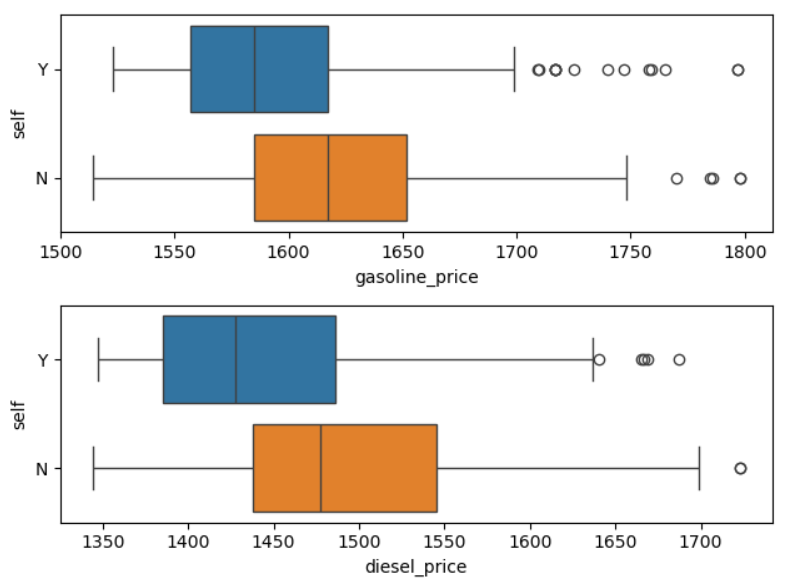
박스 플롯 또한 확인 결과 셀프 주유소가 셀프 주유소가 아닌 곳에 비해 아주 낮은 가격대에 분포하는 것으로 보이긴 하지만 그렇게 큰 차이는 없는 것으로 보입니다.
6. 히스토그램을 통해 좀 더 확실하게 분포를 확인 해 보겠습니다.
# 셀프 주유소와 일반 주유소의 가격 분포를 히스토그램으로 확인
plt.figure(figsize=(12, 6))
# 가솔린
plt.subplot(121)
sns.histplot(data=outlier_del_df, x='gasoline_price', hue='self', kde=True, element='step')
plt.title('Gasoline Price Count Compare')
plt.xlabel('Gasoline Price')
plt.ylabel('Count')
# 디젤
plt.subplot(122)
sns.histplot(data=outlier_del_df, x='diesel_price', hue='self', kde=True, element='step')
plt.title('Diesel Price Count Compare')
plt.xlabel('Diesel Price')
plt.ylabel('Count')
plt.show()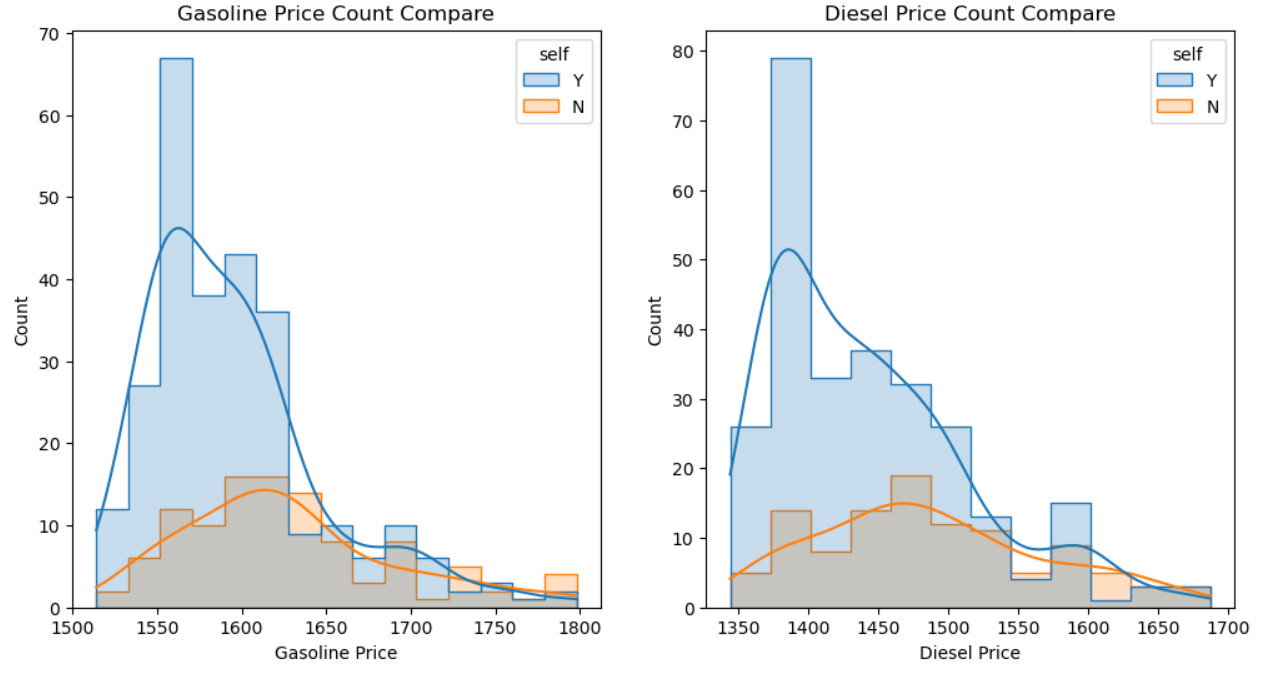
확실히 셀프 주유소가 몇 십원 정도 저렴한 가격대에 많이 분포하는 것으로 확인이 됩니다.
(그럼...주유를 할 때 돈을 아끼려면 셀프 주유소 이용이 좋아 보이기도 합니다... 제 초보적인 분석결과이니 너무 믿으시면 안됩니다..)
결론
- 이상치 제거 하지 않고 박스플롯과 최댓값과 평균값을 비교하였을 때 약 160원 정도 셀프 주유소가 훨씬 더 저렴한 것을 확인 할 수 있었습니다.
- 그래도 이상치에 의해 평균값이 올라가 잘못된 측정을 한 것일 수도 있다 판단하여 이상치를 제거하는 작업을 하고 다시 측정해보았습니다.
- 이상치를 제거 후 다시 최댓값과 평균값을 확인 해보았을 때 커봐야 20원 ~ 40원 정도의 차이로 셀프 주유소가 매우 약간 저렴한 것을 볼 수 있었습니다.
- 그리고 더 저렴한 주유소가 더 많은지에 대한 분포를 확인하기 위해 히스토그램을 사용하여 시각화한 결과 확실히 경유와 휘발유의 가격이 좀 더 싼 주유소가 많이 분포 하는 것을 확인 할 수 있었습니다.
다음 글에서는 변수 간 상관성을 제대로 분석하고 운영 여부에 따른 값의 변동이 있는지도 한 번 확인 해보겠습니다.
이 글은 제로베이스 데이터 분석 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.
이상입니다.
'Project > data analysis' 카테고리의 다른 글
| [zero-base] 이커머스 고객 Segmentation을 위한 RFM 분석 - 1 (0) | 2024.11.21 |
|---|---|
| [zero-base] 셀프 주유소는 정말로 저렴한가? (보충) (0) | 2024.10.28 |
| [zero-base] 스타벅스와 이디야 매장 거리 분석 (보충) (0) | 2024.10.23 |
| [zero-base] 스타벅스와 이디야 매장 거리 분석 (1) | 2024.10.22 |
| 데이터 분석 및 시각화하기 (영화 평점과 티켓 수익률) - Project 4 (4) | 2024.09.13 |
해당 주제는 실제로 셀프 주유소가 기름값이 더 저렴한지 궁금하여 선택한 주제 입니다. 그래서 직접 주유소 홈페이지를 들어가서 크롤링 후 실제로 더 저렴한지 분석해보겠습니다.
1. 서울시 각 구별 주유소 데이터 크롤링
from selenium import webdriver
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
from selenium.webdriver.support.select import Select
import time
# 대한민국 주유 가격 알아보는 사이트
url = 'https://www.opinet.co.kr/searRgSelect.do'
# 창 열기
driver = webdriver.Chrome()
driver.get(url)
driver.maximize_window()
# 서울 선택
select_Seoul = Select(driver.find_element(By.NAME, 'SIDO_NM0'))
select_Seoul.select_by_index(1)
# 구 선택
name = [] # 주유소 이름
address = [] # 주소
brand = [] # 상호명
gasoline_price = [] # 휘발유 가격
diesel_price = [] # 경유 가격
self = [] # 셀프 주유소 유무
car_wash = [] # 세차장 유무
charging_station = [] # 충전소 유무
maintenance = [] # 경정비 유무
convenience_store = [] # 편의점 유무
hour_24 = [] # 24시간 유무
gu = [] # 구
lat = [] # 위도
lng = [] # 경도
for i in range(1, 26):
select_gu = Select(driver.find_element(By.NAME, 'SIGUNGU_NM0'))
select_gu.select_by_index(i)
time.sleep(3) # sleep 안할 시 로딩 중 클릭으로 오류 발생
# 조회 누르기
click_search = driver.find_elements(By.CLASS_NAME, 'btn_type1')
click_search[0].click()
time.sleep(3) # sleep 안할 시 로딩 중 클릭으로 오류 발생
# 보통 휘발유 목록 전체
info_list = driver.find_elements(By.ID, 'body1')
click_gas_station = info_list[0].find_elements(By.CSS_SELECTOR,' a[href^="javascript:fn_osPop"]')
# 보통 휘발유 or 경유 목록 클릭하기
for i in range(len(click_gas_station)):
click_gas_station[i].click()
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
# 가져와야할 데이터 크롤링
name.append(soup.find('label', {'id': 'os_nm'}).text.strip())
address.append(soup.find('label', {'id': 'rd_addr'}).text.strip())
brand.append(soup.find('label', {'id': 'poll_div_nm'}).text.strip())
gasoline_price.append(int(soup.find('label', {'id': 'b027_p'}).text.strip().replace(",", "")))
diesel_price.append(int(soup.find('label', {'id': 'd047_p'}).text.strip().replace(",", "")))
self_TF = bool(soup.find('img', {'alt': '셀프주유소'}))
if self_TF:
self.append('Y')
else:
self.append('N')
car_wash_TF = 'off' in str(soup.find('img', {'id': 'cwsh_yn'}))
if car_wash_TF:
car_wash.append('N')
else :
car_wash.append('Y')
charging_station_TF = 'off' in str(soup.find('img', {'id': 'lpg_yn'}))
if charging_station_TF:
charging_station.append('N')
else :
charging_station.append('Y')
maintenance_TF = 'off' in str(soup.find('img', {'id': 'maint_yn'}))
if maintenance_TF:
maintenance.append('N')
else :
maintenance.append('Y')
convenience_store_TF = 'off' in str(soup.find('img', {'id': 'cvs_yn'}))
if convenience_store_TF:
convenience_store.append('N')
else :
convenience_store.append('Y')
hour_24_TF = 'off' in str(soup.find('img', {'id': 'sel24_yn'}))
if hour_24_TF:
hour_24.append('N')
else :
hour_24.append('Y')
gu.append(address[0].split(' ')[1])
driver.quit()
import pandas as pd
df = pd.DataFrame({
'name': name,
'address': address,
'brand': brand,
'gasoline_price': gasoline_price,
'diesel_price': diesel_price,
'self': self,
'car_wash': car_wash,
'charging_station': charging_station,
'maintenance': maintenance,
'convenience_store': convenience_store,
'hour_24': hour_24,
'gu': gu
})
df저는 리스트에 각각의 값들을 모두 저장하는 바람에 코드가 매우 길어졌으나 꼭 크롤링을 저처럼 하시지 않아도 됩니다.
코드는 매우 길지만 저희가 원하는 결과를 딱 가져온 것을 확인 할 수 있었습니다.
2. 주유소에 추가되어있는 운영 여부에 따른 상관성 분석
df.drop(columns=['name','address', 'brand','gu'], axis=1)
.replace({'Y': 1, 'N': 0}).corr()셀프 주유수 여부에서 그나마 약한 상관관계를 보입니다.
하지만 저는 피어슨 상관계수(corr)를 사용하였으나, 매우 큰 실수 였었습니다. 왜냐하면 범주형 변수(Y/N이 들어있는 변수)를 피어슨 상관계수를 사용하여 분석하는데에는 한계가 있기 때문입니다.
해결방법!!
- 포인트 바이세리얼 상관계수 계산
연속형 변수와 이진형 범주 변수를 각각 나눠서 포인트 바이세리얼 상관계수를 계산할 수 있습니다. - 각 이진 변수와 연속 변수 간의 t-검정
각 이진 변수(Y/N 변환 값)와 연속 변수 간의 차이가 유의미한지 확인하는 t-검정을 사용할 수 있습니다. 예를 들어, 기름값을 두 그룹(Y와 N)에 나눠 평균 차이가 있는지를 분석하여 상관성을 확인합니다. - 로지스틱 회귀 분석
기름값의 상하위 구간을 기준으로 이진 종속 변수를 만들어, 각 변수의 기여도를 로지스틱 회귀로 확인하는 방법도 좋습니다.
해당 문제는 다음 글에서 해결해보겠습니다.
3. Self 주유소와 아닌 주유소의 휘발유 가격 대조
df.groupby('self')[['gasoline_price', 'diesel_price']].agg(['max', 'mean'])
휘발유 가격과 경유 가격에서 제일 큰 값으로 비교해본 결과 셀프 주유소가 아닌 곳의 가격이 매우 큰 것으로 확인되었습니다. 그리고 가격 평균으로 확인 해본 결과 셀프 주유소가 약 160원 정도 저렴한 것으로 확인 되었습니다.
하지만 셀프 주유소가 아닌 곳의 outlier를 확인하여 이로 인한 평균 증가인 것인지 박스 플롯을 통해 확인 해보겠습니다.
4. 박스플롯 생성 및 Outlier 제거
import seaborn as sns
import matplotlib.pyplot as plt
plt.subplot(211)
sns.boxplot(data=df, y=df['self'], x=df['gasoline_price'], hue=df['self']);
plt.subplot(212)
sns.boxplot(data=df, y=df['self'], x=df['diesel_price'], hue=df['self']);
plt.tight_layout()Boxplot으로 확인 해본 결과 두 개의 그래프 모두 Outlier가 좀 보이며(특히 셀프 주유소가 아닌 곳은 말도 안되게 비쌉니다...) 셀프 주유소가 아닌 곳 들은 대체로 셀프 주유소보다 높은 가격대에 분포하는 것으로 보입니다.
셀프 주유소에서의 outlier도 확실히 이상하긴 합니다. 평균이 1600원 정도인데 약 600원 차이도 보이기도 하구요..!!
Q1 = df[['gasoline_price', 'diesel_price']].quantile(q=0.25) # q1 값
Q3 = df[['gasoline_price', 'diesel_price']].quantile(q=0.75) # q3 값
IQR = Q3 - Q1
# 가솔린 이상치 제거 후 DataFrame
gasoline_outlier_del_df = df[(df['gasoline_price'] > Q1['gasoline_price'] - 1.5 * IQR['gasoline_price']) & (df['gasoline_price'] < Q3['gasoline_price'] + 1.5 * IQR['gasoline_price'])]
# 경유 이상치 제거 후 DataFrame
diesel_outlier_del_df = df[(df['diesel_price'] > Q1['diesel_price'] - 1.5 * IQR['diesel_price']) & (df['diesel_price'] < Q3['diesel_price'] + 1.5 * IQR['diesel_price'])]IQR을 활용하여 이상치를 제거하였습니다.
5. 가격 비교와 박스플롯으로 다시 확인하기
그래도 전 보다는 확실히 평균과 max값이 좀 더 안정된 것으로 확인 됩니다.
그리고 가솔린의 최대값은 거의 차이가 나지 않지만 평균 가격은 약 25원 정도의 차이가 있어 보입니다.
경유의 최대값 또한 거의 차이가 없으며 평균 가격은 약 50원 정도의 차이가 있습니다.
plt.subplot(211)
sns.boxplot(data=gasoline_outlier_del_df,
y=gasoline_outlier_del_df['self'],
x=gasoline_outlier_del_df['gasoline_price'],
hue=gasoline_outlier_del_df['self']);
plt.subplot(212)
sns.boxplot(data=diesel_outlier_del_df,
y=diesel_outlier_del_df['self'],
x=diesel_outlier_del_df['diesel_price'],
hue=diesel_outlier_del_df['self']);
plt.tight_layout()박스 플롯 또한 확인 결과 셀프 주유소가 셀프 주유소가 아닌 곳에 비해 아주 낮은 가격대에 분포하는 것으로 보이긴 하지만 그렇게 큰 차이는 없는 것으로 보입니다.
6. 히스토그램을 통해 좀 더 확실하게 분포를 확인 해 보겠습니다.
# 셀프 주유소와 일반 주유소의 가격 분포를 히스토그램으로 확인
plt.figure(figsize=(12, 6))
# 가솔린
plt.subplot(121)
sns.histplot(data=outlier_del_df, x='gasoline_price', hue='self', kde=True, element='step')
plt.title('Gasoline Price Count Compare')
plt.xlabel('Gasoline Price')
plt.ylabel('Count')
# 디젤
plt.subplot(122)
sns.histplot(data=outlier_del_df, x='diesel_price', hue='self', kde=True, element='step')
plt.title('Diesel Price Count Compare')
plt.xlabel('Diesel Price')
plt.ylabel('Count')
plt.show()확실히 셀프 주유소가 몇 십원 정도 저렴한 가격대에 많이 분포하는 것으로 확인이 됩니다.
(그럼...주유를 할 때 돈을 아끼려면 셀프 주유소 이용이 좋아 보이기도 합니다... 제 초보적인 분석결과이니 너무 믿으시면 안됩니다..)
결론
- 이상치 제거 하지 않고 박스플롯과 최댓값과 평균값을 비교하였을 때 약 160원 정도 셀프 주유소가 훨씬 더 저렴한 것을 확인 할 수 있었습니다.
- 그래도 이상치에 의해 평균값이 올라가 잘못된 측정을 한 것일 수도 있다 판단하여 이상치를 제거하는 작업을 하고 다시 측정해보았습니다.
- 이상치를 제거 후 다시 최댓값과 평균값을 확인 해보았을 때 커봐야 20원 ~ 40원 정도의 차이로 셀프 주유소가 매우 약간 저렴한 것을 볼 수 있었습니다.
- 그리고 더 저렴한 주유소가 더 많은지에 대한 분포를 확인하기 위해 히스토그램을 사용하여 시각화한 결과 확실히 경유와 휘발유의 가격이 좀 더 싼 주유소가 많이 분포 하는 것을 확인 할 수 있었습니다.
다음 글에서는 변수 간 상관성을 제대로 분석하고 운영 여부에 따른 값의 변동이 있는지도 한 번 확인 해보겠습니다.
이 글은 제로베이스 데이터 분석 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.
이상입니다.
'Project > data analysis' 카테고리의 다른 글
| [zero-base] 이커머스 고객 Segmentation을 위한 RFM 분석 - 1 (0) | 2024.11.21 |
|---|---|
| [zero-base] 셀프 주유소는 정말로 저렴한가? (보충) (0) | 2024.10.28 |
| [zero-base] 스타벅스와 이디야 매장 거리 분석 (보충) (0) | 2024.10.23 |
| [zero-base] 스타벅스와 이디야 매장 거리 분석 (1) | 2024.10.22 |
| 데이터 분석 및 시각화하기 (영화 평점과 티켓 수익률) - Project 4 (4) | 2024.09.13 |