이전 글에서 언급했던 범주형 변수(Y/N이 들어있는 변수)를 피어슨 상관계수를 사용하여 분석하였던 문제를 해결하기 위해 포인트 바이세리얼 상관계수와 t-검정을 활용하여 변수간 상관성을 다시 분석해보았습니다.
코드를 통해 설명하겠습니다.
1. stats 라이브러리의 pointbiserialr을 활용하여 상관성 확인
from scipy.stats import pointbiserialr
def pointbiserialr_calc(price, column):
correlation, p_value = pointbiserialr(df_replace[column], df_replace[price])
print(f"{price}와 {column}의 포인트 바이세리얼 상관계수: {round(correlation, 6)}")
print("p-value:", p_value)우선 각각의 변수들을 모두 확인해야 하기 때문에 함수로 만들어주는 작업을 하였습니다.
이제 price 변수에는 수치형 변수(휘발유, 디젤 가격)를 넣어주면 되는 것이고 column 변수에는 범주형 변수(운영여부)를 넣어 주면 됩니다.
그리고 해당 pointbiserialr을 사용하면 동시에 t-검정도 가능합니다. 왜냐하면 해당 함수를 사용하게 되면 p-value 또한 동시에 같이 얻을 수 있기 때문입니다.
2. 매개변수에 맞는 컬럼 값 넣어주고 결과 확인하기
# Y -> 1, N -> 0
df_replace = df.replace({'Y': 1, 'N': 0})
for i in range(5, len(df_replace.columns) - 1):
pointbiserialr_calc(df_replace.columns[i], 'gasoline_price')
print()
for i in range(5, len(df_replace.columns) - 1):
pointbiserialr_calc(df_replace.columns[i], 'diesel_price')
print()우선 range 부분에서는 df_replace.colmns는 리스트로 출력 됩니다. 그리고 5번째 열 부터 마지막 번째 열 - 1을 해주면 어떤 운영 여부의 컬럼인지 나오게 됩니다.
결과를 확인 해보겠습니다.

이렇게 각각의 변수에 따른 상관 계수와 p-value를 확인 할 수 있습니다.
해당 결과를 해석해겠습니다.
우선 self와 휘발유 또는 경유의 상관계수는 -0.45로 매우 높은 상관관계를 가지는 것을 확인 할 수 있습니다.
또 다른 의미로는 self가 0일 경우 가격이 오른다는 의미로 볼 수 있습니다. 1인 경우는 낮아지는 것이구요
또한 p-value 또한 매우 작은 수로 측정이 되었습니다.(우연히 발생했을 확률이 5% 미만으로 유의미하다는 것을 알 수 있습니다.)
다른 변수들은 모두 상관계수의 값이 매우 낮으며, p-value 값은 매우 높아(우연히 발생했을 확률이 높기 때문에 서로의 상관성이 매우 떨어지는 것으로 판단)
이렇듯 결과는 self 주유소 여부에 따라 가격 변동이 있을 뿐 다른 운영을 한다해서 기름 값이 변동되는 것은 아니라는 것을 알 수 있었습니다.
3. 측정된 상관계수를 heatmap으로 시각화하기
import seaborn as sns
import matplotlib.pyplot as plt
# 상관계수 데이터 정리
correlation_data = {
'gasoline_price': {
'self': -0.456811,
'car_wash': 0.013931,
'charging_station': 0.013169,
'maintenance': -0.066057,
'convenience_store': -0.016601,
'hour_24': 0.048696
},
'diesel_price': {
'self': -0.449904,
'car_wash': 0.025341,
'charging_station': 0.037443,
'maintenance': -0.053068,
'convenience_store': -0.005395,
'hour_24': 0.056113
}
}
# 데이터프레임 생성
correlation_df = pd.DataFrame(correlation_data)
# 히트맵 생성
plt.figure(figsize=(8, 6))
sns.heatmap(correlation_df, annot=True, cmap='coolwarm', center=0)
plt.title("Point-Biserial Correlation Heatmap")
plt.show()원래는 각각의 값을 리스트에 추가하여 만들면 되지만 직접 넣는 것이 좀 더 편하고 가독성도 좋아 일일이 써넣었습니다.
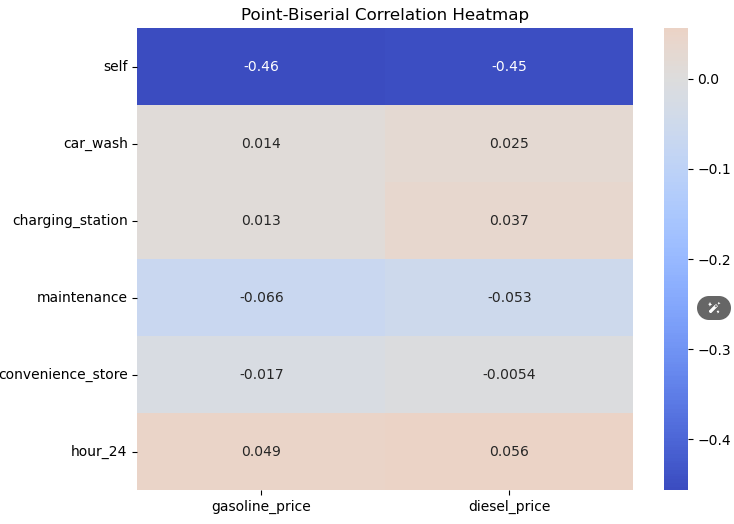
heatmap으로 확인하니 훨씬 눈에 정확히 들어옵니다. 위에서 말했듯이 self 변수가 가격에 대한 상관성이 매우 큰 것으로 확인 됩니다.
이와 같이 범주형 변수일 경우에는 그저 피어슨 상관계수를 무작정 사용하면 안되는 것을 알 수 있었습니다. 그리고 범주형 변수일 때 확인 할 수 있는 상관계수 계산으로는 포인트 바이세리얼과 p-value를 통해 확인 할 수 있고 직접 실습해보니 확실히 알아 갈 수 있었습니다.
글은 제로베이스 데이터 분석 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.
이상입니다.
'Project > data analysis' 카테고리의 다른 글
| [zero-base] 이커머스 고객 Segmentation을 위한 RFM 분석 - 2 (1) | 2024.11.22 |
|---|---|
| [zero-base] 이커머스 고객 Segmentation을 위한 RFM 분석 - 1 (0) | 2024.11.21 |
| [zero-base] 셀프 주유소는 정말로 저렴한가? (1) | 2024.10.25 |
| [zero-base] 스타벅스와 이디야 매장 거리 분석 (보충) (0) | 2024.10.23 |
| [zero-base] 스타벅스와 이디야 매장 거리 분석 (1) | 2024.10.22 |