🔊Process03
RFM 활용 서비스 이용 수준 측정
3.1 Scailing Data
# ▶ Min max scale = 최대값을 1, 최소값을 0으로 표준화하는 기법
from sklearn.preprocessing import minmax_scale
# ▶ 최근성은 숫자가 작을수록, 즉 최근 구매일이 얼마 지나지 않은 고객이 더 점수가 높음 그래서 1을 빼주었음.
rfm['Recency'] = minmax_scale(rfm['Recency'], axis=0, copy=True)
rfm['Recency'] = 1-rfm['Recency']
rfm['Frequency'] = minmax_scale(rfm['Frequency'], axis=0, copy=True)
rfm['Monetary'] = minmax_scale(rfm['Monetary'], axis=0, copy=True)
# ▶ Score
rfm['Score']=rfm['Recency']+rfm['Frequency']+rfm['Monetary']
# ▶ Score scaling 100 socre
rfm
# ▶ 100점을 곱해서 100점 만점으로 scaling
rfm['Score']=minmax_scale(rfm['Score'], axis=0, copy=True)*100
rfm['Score']=round(rfm['Score'],0)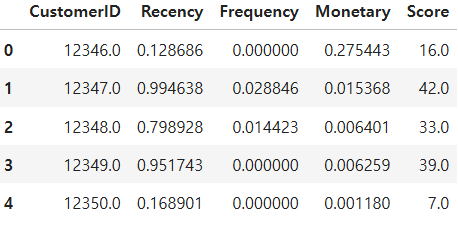
minmax스케일링은 1과 0사이의 값으로 바꿔줍니다. 그리고 recency의 값은 숫자가 낮을 수록 좋은 것입니다. 왜냐하면 recency는 고객이 물품을 구매한 최근 주기를 의미하기 때문입니다. (1일 주기가 제일 좋은 것이겠죵?)
하지만 스케일링을 하게 되면 작은 값으로 변환 될 것입니다. 그래서 숫자를 크게 바꿔주기 위해 1을 빼줍니다.
그리고 RFM SCORE를 만들어줍니다. 저는 R, F, M값을 모두 더해주었습니다. 그리고 마무리로 10을 곱하여 보기 편하게 변환 해주었습니다.
3.2 Grade(점수) 구간화
# ▶ 점수별로 고객의 등급을 부여
# 60점 이상 Very storong
# 40~60점 Storng
# 20~40점 Normal
# 10~20점 Weak
# 0~10점 Very Weak
rfm['Grade'] = rfm['Score'].apply(lambda x : '01.Very Strong' if x>=60 else
('02.Strong' if x>=40 else
('03.Normal' if x>=20 else
('04.Weak' if x>=10 else '05.Very Weak'))))
# ▶ 기존 Data에 고객의 등급(Grade) Data를 left join
df = pd.merge(df, rfm, how='left', on='CustomerID')
# ▶ 지표 기획에 앞서, 년월만 새로운 col로 정의 (※ 월별 분석을 하기위한 준비과정)
df['Date_1'] = df["Date"].dt.strftime("%Y-%m")
df.head(5)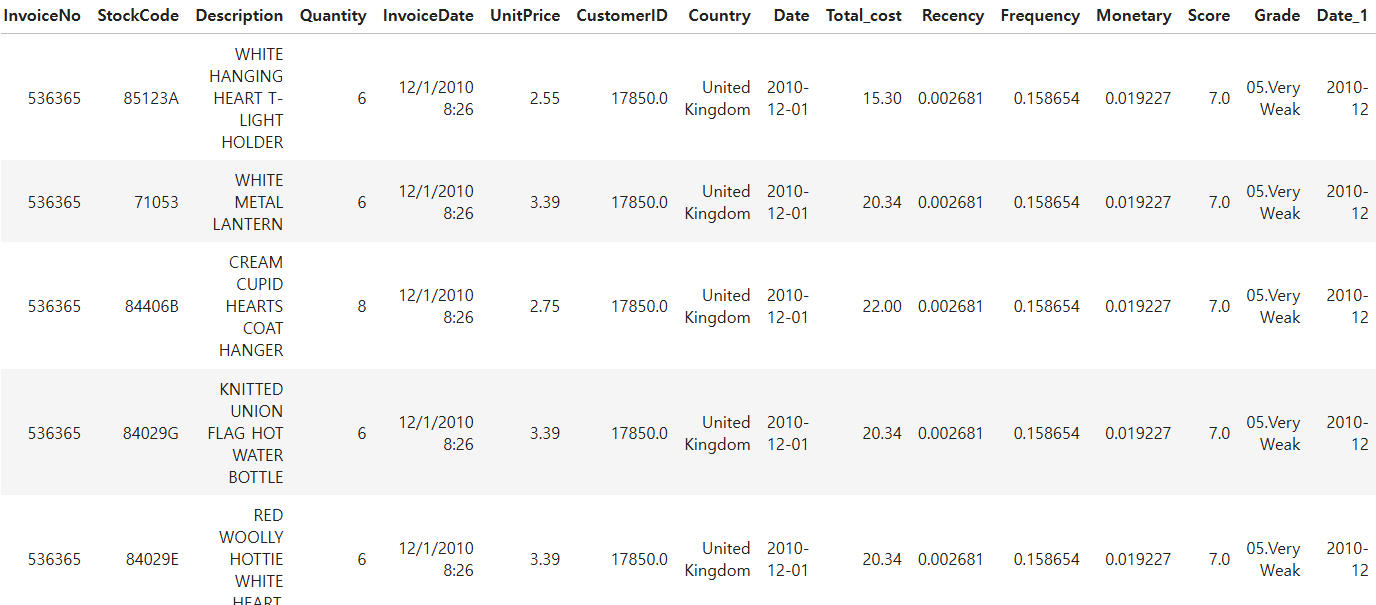
우선 위의 코드에 있는 주석의 조건에 맞게 저는 RFM Score를 이용하여 구간마다 등급을 매겨주었습니다.
그리고 원래있는 df 테이블에 rfm테이블을 merge하여 합쳐주었습니다.
마지막으로 월별 분석을 하기위해 Date 컬럼에 있는 년/월/일/시에서 년-월만 가져와주었습니다.
3.3 지표 기획
월 별 이용 고객(MAU) 현황
df_cus = df.groupby('Date_1', as_index=False)['CustomerID'].nunique()
plt.plot(df_cus['Date_1'], df_cus['CustomerID'], label='Customer')
plt.legend()
plt.gcf().set_size_inches(25, 5)
plt.show()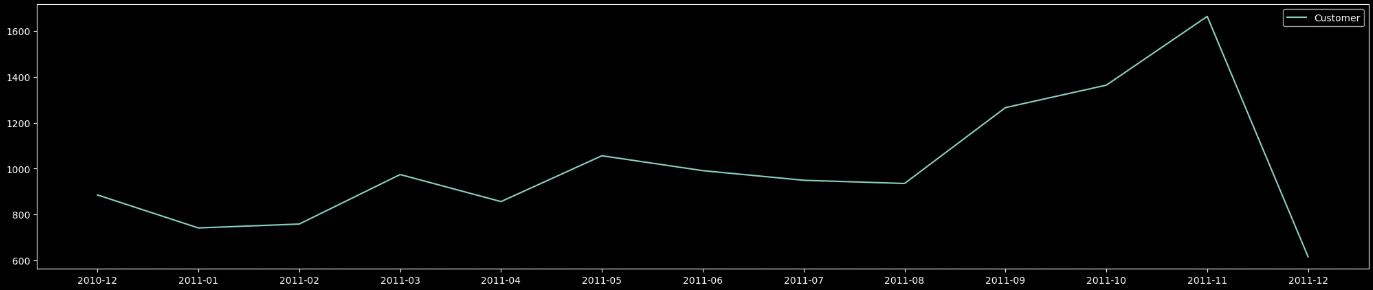
월별로 보았을 때 고객 이용 수가 점점 늘어나다가 2011년 8월에 잠깐 떨어지고 다시 쭉 올라가는 것을 볼 수 있습니다.(우상향 그래프)
여기서 12월에서 수직하강 하는 이유는 저희 데이터는 12월 9일까지의 데이터 밖에 없기에 12월 데이터의 부족으로 인해 이렇게 표현되는 것입니다.
그리고 MAU 그래프의 우상향 추세를 띄는 것으로 보아 좋은 성적을 거두고 있는 것 같습니다.
월 별 이용 건수 구하기
df_cnt = df.groupby('Date_1', as_index=False)['InvoiceNo'].nunique()
plt.plot(df_cnt['Date_1'], df_cnt['InvoiceNo'], label='Customer_cnt')
plt.legend()
plt.gcf().set_size_inches(25, 5)
plt.show()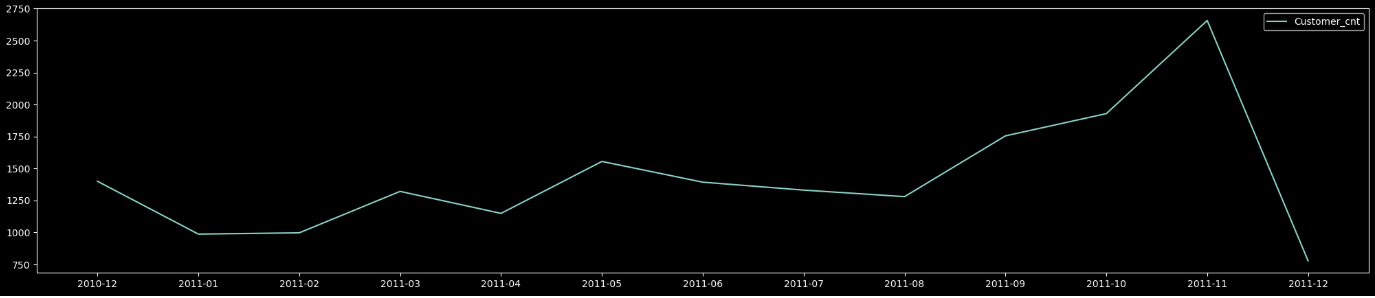
월 별 이용 건수 또한 위의 월 별 이용 고객의 그래프와 비슷한 추세를 보이는 것으로 확인 되었습니다.
월 별 이용 국가 - 충성도 높은 국가 확인하기
# 충성도 높은 국가 확인하기
pd.DataFrame(df.groupby(['Country'])['InvoiceNo'].nunique().sort_values(ascending=False)).head(10)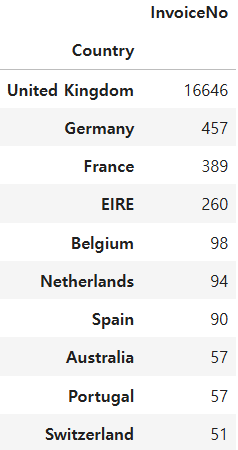
UK에서 압도적으로 많이 이용하는 것으로 보입니다. 아무래도 해당 플랫폼이 UK에 있는 플랫폼으로 예상되며 마케팅을 할 경우 타겟팅 대상 국가를 UK로 하는 것도 좋은 전략이 될 것 같습니다.
3.4 월 별 Grade 이용 비중 - 매우 중요
df_grade = df.groupby(['Date_1','Grade'], as_index=False)['CustomerID'].nunique()
df_pivot = pd.pivot_table(df_grade, # 피벗할 데이터프레임
index = 'Date_1', # 행 위치에 들어갈 열
columns = 'Grade', # 열 위치에 들어갈 열
values = 'CustomerID') # 데이터로 사용할 열
df_pivot.fillna(0, inplace=True)
df_pivot['total'] = df_pivot['01.Very Strong'] + df_pivot['02.Strong'] + df_pivot['03.Normal'] + df_pivot['04.Weak'] + df_pivot['05.Very Weak']
df_pivot.iloc[:,0] = (df_pivot.iloc[:,0] / df_pivot['total'])
df_pivot.iloc[:,1] = (df_pivot.iloc[:,1] / df_pivot['total'])
df_pivot.iloc[:,2] = (df_pivot.iloc[:,2] / df_pivot['total'])
df_pivot.iloc[:,3] = (df_pivot.iloc[:,3] / df_pivot['total'])
df_pivot.iloc[:,4] = (df_pivot.iloc[:,4] / df_pivot['total'])
df_pivot.drop(['total'], axis=1, inplace=True)
import warnings
warnings.filterwarnings('ignore') # 모든 경고 메시지를 무시합니다.
# 그래프 스타일을 'dark_background'로 설정 (어두운 배경)
plt.style.use(['dark_background'])
# 수평 누적 막대 그래프 생성
# - `df_pivot`: 데이터프레임으로, 시각화할 데이터입니다.
# - `kind='barh'`: 수평 막대 그래프를 그립니다.
# - `stacked=True`: 막대를 누적 형태로 표시합니다.
# - `title='year amt'`: 그래프 제목을 'year amt'로 설정합니다.
# - `rot=0`: y축 레이블의 회전 각도를 0도로 설정합니다.
ax = df_pivot.plot(kind='barh', stacked=True, title='year amt', rot=0)
# 막대 그래프에 값 레이블 추가
# - `ax.patches`는 그래프의 막대(bar) 객체 리스트입니다.
for p in ax.patches:
left, bottom, width, height = p.get_bbox().bounds # 막대의 위치와 크기 정보를 가져옵니다.
# 막대의 중앙에 값 레이블을 추가합니다.
# - `width*100`: 막대의 너비에 100을 곱한 값을 표시 (예: 백분율 계산)
# - `xy=(left + width/2, bottom + height/2)`: 막대의 중앙 좌표
# - `ha='center'`: 텍스트 정렬을 중앙으로 설정
# - `color='black'`: 텍스트 색상은 검정색
ax.annotate('%.1f' % (width * 100), xy=(left + width / 2, bottom + height / 2), ha='center', color='black')
# 그래프 테두리(box)를 표시하지 않음
plt.box(False)
# 그래프의 크기를 25인치 x 15인치로 설정
plt.gcf().set_size_inches(25, 15)
# 그래프 출력
plt.show()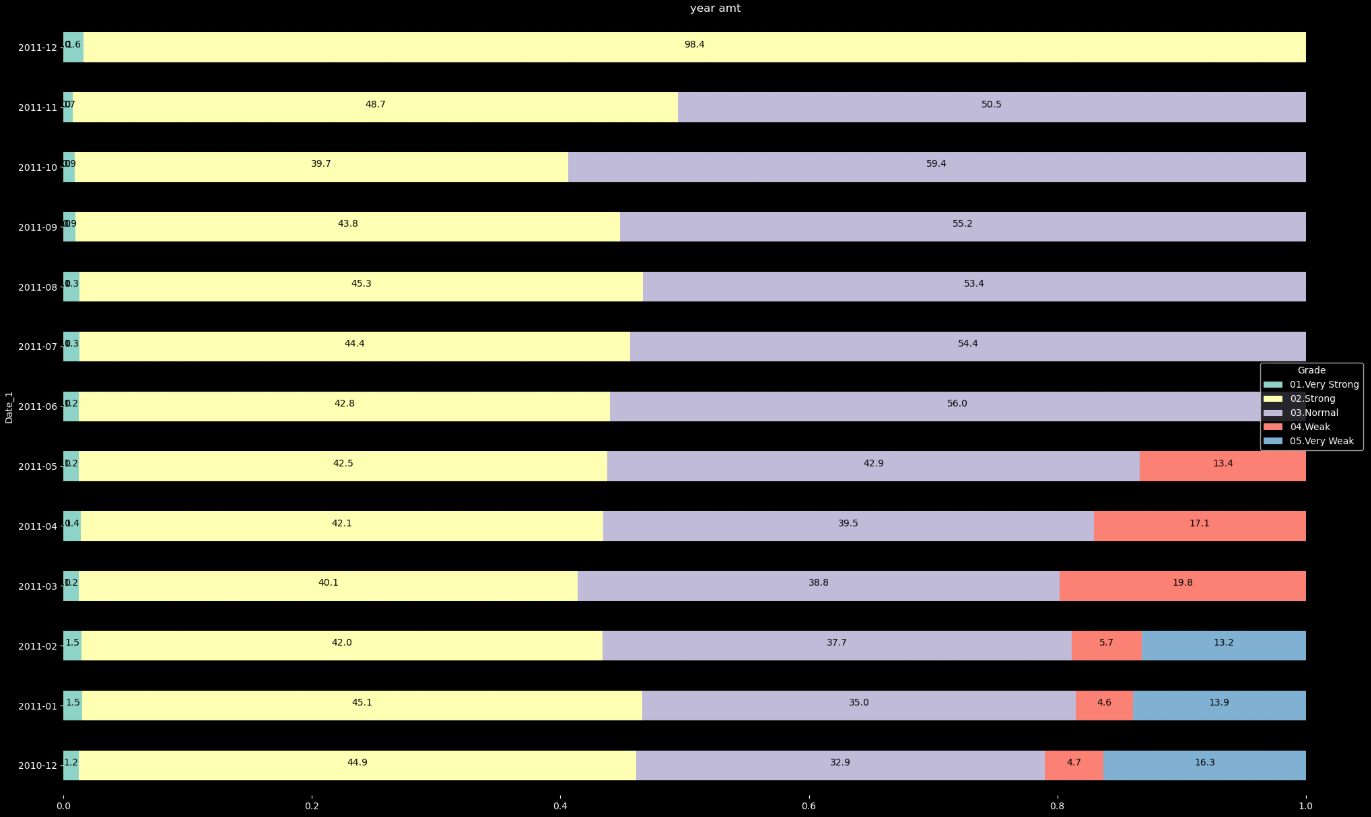
- 월 별 Grade 이용 비중을 확인 하기 위해 우선 Date_1(년-월), Grade를 기준으로 묶어준 뒤 고객 ID의 개수를 세어 줍니다. 그러면 월을 기준으로 등급 별 고객들의 이용 고객 수를 알 수 있게 됩니다.
- pivot을 사용하여 데이터 테이블을 따로 만들어 줍니다. 그리고 각 비중을 구하기 위해 등급마다 존재하는 고객 수를 모두 더해준 total 컬럼을 따로 만들어 줍니다.
- 모든 테이블의 값에 열을 기준으로 모두 total 값을 나누어 줍니다!! 그러면 테이블의 값들이 위의 그래프와 같이 100%를 기준으로 각 등급의 차지하는 비율의 값이 구해지게 됩니다!!
- 시각화 방법은 위의 주석에 달아놓았습니다.
해당 그래프 확인 결과 아래 2개의 등급이 점차 사라지는 것을 확인 할 수 있습니다. 어떻게 보면 좋은 현상으로는 보입니다. 하지만 여기서 문제는 상위 등급의 비율이 시간이 지나도 변하지 않는 것이 보입니다.
즉, 마케팅 대상을 상위 등급 고객들에 포커스를 맞추는 것이 좋을 것 같습니다.
저는 팀프로젝트를 하였을 때 RFM을 통해 등급을 기준으로 데이터가 어떻게 변화하는지만 보면 되는 것인 줄 알았으나, 해당 프로젝트를 해보면 RFM을 통해 무엇을 봐야 할 지(마지막 그래프에 해당하는 RFM 등급에 따른 이용 비중) 정확히 알 수 있었습니다.
그리고 RFM 분석에 대해서도 확실하게 이해하기 좋은 프로젝트였습니다.
이 글은 제로베이스 데이터 분석 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.
이상입니다.
'Project > data analysis' 카테고리의 다른 글
| [zero-base] 이커머스 고객 Segmentation을 위한 RFM 분석 - 1 (0) | 2024.11.21 |
|---|---|
| [zero-base] 셀프 주유소는 정말로 저렴한가? (보충) (0) | 2024.10.28 |
| [zero-base] 셀프 주유소는 정말로 저렴한가? (1) | 2024.10.25 |
| [zero-base] 스타벅스와 이디야 매장 거리 분석 (보충) (0) | 2024.10.23 |
| [zero-base] 스타벅스와 이디야 매장 거리 분석 (1) | 2024.10.22 |
🔊Process03
RFM 활용 서비스 이용 수준 측정
3.1 Scailing Data
# ▶ Min max scale = 최대값을 1, 최소값을 0으로 표준화하는 기법
from sklearn.preprocessing import minmax_scale
# ▶ 최근성은 숫자가 작을수록, 즉 최근 구매일이 얼마 지나지 않은 고객이 더 점수가 높음 그래서 1을 빼주었음.
rfm['Recency'] = minmax_scale(rfm['Recency'], axis=0, copy=True)
rfm['Recency'] = 1-rfm['Recency']
rfm['Frequency'] = minmax_scale(rfm['Frequency'], axis=0, copy=True)
rfm['Monetary'] = minmax_scale(rfm['Monetary'], axis=0, copy=True)
# ▶ Score
rfm['Score']=rfm['Recency']+rfm['Frequency']+rfm['Monetary']
# ▶ Score scaling 100 socre
rfm
# ▶ 100점을 곱해서 100점 만점으로 scaling
rfm['Score']=minmax_scale(rfm['Score'], axis=0, copy=True)*100
rfm['Score']=round(rfm['Score'],0)minmax스케일링은 1과 0사이의 값으로 바꿔줍니다. 그리고 recency의 값은 숫자가 낮을 수록 좋은 것입니다. 왜냐하면 recency는 고객이 물품을 구매한 최근 주기를 의미하기 때문입니다. (1일 주기가 제일 좋은 것이겠죵?)
하지만 스케일링을 하게 되면 작은 값으로 변환 될 것입니다. 그래서 숫자를 크게 바꿔주기 위해 1을 빼줍니다.
그리고 RFM SCORE를 만들어줍니다. 저는 R, F, M값을 모두 더해주었습니다. 그리고 마무리로 10을 곱하여 보기 편하게 변환 해주었습니다.
3.2 Grade(점수) 구간화
# ▶ 점수별로 고객의 등급을 부여
# 60점 이상 Very storong
# 40~60점 Storng
# 20~40점 Normal
# 10~20점 Weak
# 0~10점 Very Weak
rfm['Grade'] = rfm['Score'].apply(lambda x : '01.Very Strong' if x>=60 else
('02.Strong' if x>=40 else
('03.Normal' if x>=20 else
('04.Weak' if x>=10 else '05.Very Weak'))))
# ▶ 기존 Data에 고객의 등급(Grade) Data를 left join
df = pd.merge(df, rfm, how='left', on='CustomerID')
# ▶ 지표 기획에 앞서, 년월만 새로운 col로 정의 (※ 월별 분석을 하기위한 준비과정)
df['Date_1'] = df["Date"].dt.strftime("%Y-%m")
df.head(5)우선 위의 코드에 있는 주석의 조건에 맞게 저는 RFM Score를 이용하여 구간마다 등급을 매겨주었습니다.
그리고 원래있는 df 테이블에 rfm테이블을 merge하여 합쳐주었습니다.
마지막으로 월별 분석을 하기위해 Date 컬럼에 있는 년/월/일/시에서 년-월만 가져와주었습니다.
3.3 지표 기획
월 별 이용 고객(MAU) 현황
df_cus = df.groupby('Date_1', as_index=False)['CustomerID'].nunique()
plt.plot(df_cus['Date_1'], df_cus['CustomerID'], label='Customer')
plt.legend()
plt.gcf().set_size_inches(25, 5)
plt.show()월별로 보았을 때 고객 이용 수가 점점 늘어나다가 2011년 8월에 잠깐 떨어지고 다시 쭉 올라가는 것을 볼 수 있습니다.(우상향 그래프)
여기서 12월에서 수직하강 하는 이유는 저희 데이터는 12월 9일까지의 데이터 밖에 없기에 12월 데이터의 부족으로 인해 이렇게 표현되는 것입니다.
그리고 MAU 그래프의 우상향 추세를 띄는 것으로 보아 좋은 성적을 거두고 있는 것 같습니다.
월 별 이용 건수 구하기
df_cnt = df.groupby('Date_1', as_index=False)['InvoiceNo'].nunique()
plt.plot(df_cnt['Date_1'], df_cnt['InvoiceNo'], label='Customer_cnt')
plt.legend()
plt.gcf().set_size_inches(25, 5)
plt.show()월 별 이용 건수 또한 위의 월 별 이용 고객의 그래프와 비슷한 추세를 보이는 것으로 확인 되었습니다.
월 별 이용 국가 - 충성도 높은 국가 확인하기
# 충성도 높은 국가 확인하기
pd.DataFrame(df.groupby(['Country'])['InvoiceNo'].nunique().sort_values(ascending=False)).head(10)UK에서 압도적으로 많이 이용하는 것으로 보입니다. 아무래도 해당 플랫폼이 UK에 있는 플랫폼으로 예상되며 마케팅을 할 경우 타겟팅 대상 국가를 UK로 하는 것도 좋은 전략이 될 것 같습니다.
3.4 월 별 Grade 이용 비중 - 매우 중요
df_grade = df.groupby(['Date_1','Grade'], as_index=False)['CustomerID'].nunique()
df_pivot = pd.pivot_table(df_grade, # 피벗할 데이터프레임
index = 'Date_1', # 행 위치에 들어갈 열
columns = 'Grade', # 열 위치에 들어갈 열
values = 'CustomerID') # 데이터로 사용할 열
df_pivot.fillna(0, inplace=True)
df_pivot['total'] = df_pivot['01.Very Strong'] + df_pivot['02.Strong'] + df_pivot['03.Normal'] + df_pivot['04.Weak'] + df_pivot['05.Very Weak']
df_pivot.iloc[:,0] = (df_pivot.iloc[:,0] / df_pivot['total'])
df_pivot.iloc[:,1] = (df_pivot.iloc[:,1] / df_pivot['total'])
df_pivot.iloc[:,2] = (df_pivot.iloc[:,2] / df_pivot['total'])
df_pivot.iloc[:,3] = (df_pivot.iloc[:,3] / df_pivot['total'])
df_pivot.iloc[:,4] = (df_pivot.iloc[:,4] / df_pivot['total'])
df_pivot.drop(['total'], axis=1, inplace=True)
import warnings
warnings.filterwarnings('ignore') # 모든 경고 메시지를 무시합니다.
# 그래프 스타일을 'dark_background'로 설정 (어두운 배경)
plt.style.use(['dark_background'])
# 수평 누적 막대 그래프 생성
# - `df_pivot`: 데이터프레임으로, 시각화할 데이터입니다.
# - `kind='barh'`: 수평 막대 그래프를 그립니다.
# - `stacked=True`: 막대를 누적 형태로 표시합니다.
# - `title='year amt'`: 그래프 제목을 'year amt'로 설정합니다.
# - `rot=0`: y축 레이블의 회전 각도를 0도로 설정합니다.
ax = df_pivot.plot(kind='barh', stacked=True, title='year amt', rot=0)
# 막대 그래프에 값 레이블 추가
# - `ax.patches`는 그래프의 막대(bar) 객체 리스트입니다.
for p in ax.patches:
left, bottom, width, height = p.get_bbox().bounds # 막대의 위치와 크기 정보를 가져옵니다.
# 막대의 중앙에 값 레이블을 추가합니다.
# - `width*100`: 막대의 너비에 100을 곱한 값을 표시 (예: 백분율 계산)
# - `xy=(left + width/2, bottom + height/2)`: 막대의 중앙 좌표
# - `ha='center'`: 텍스트 정렬을 중앙으로 설정
# - `color='black'`: 텍스트 색상은 검정색
ax.annotate('%.1f' % (width * 100), xy=(left + width / 2, bottom + height / 2), ha='center', color='black')
# 그래프 테두리(box)를 표시하지 않음
plt.box(False)
# 그래프의 크기를 25인치 x 15인치로 설정
plt.gcf().set_size_inches(25, 15)
# 그래프 출력
plt.show()- 월 별 Grade 이용 비중을 확인 하기 위해 우선 Date_1(년-월), Grade를 기준으로 묶어준 뒤 고객 ID의 개수를 세어 줍니다. 그러면 월을 기준으로 등급 별 고객들의 이용 고객 수를 알 수 있게 됩니다.
- pivot을 사용하여 데이터 테이블을 따로 만들어 줍니다. 그리고 각 비중을 구하기 위해 등급마다 존재하는 고객 수를 모두 더해준 total 컬럼을 따로 만들어 줍니다.
- 모든 테이블의 값에 열을 기준으로 모두 total 값을 나누어 줍니다!! 그러면 테이블의 값들이 위의 그래프와 같이 100%를 기준으로 각 등급의 차지하는 비율의 값이 구해지게 됩니다!!
- 시각화 방법은 위의 주석에 달아놓았습니다.
해당 그래프 확인 결과 아래 2개의 등급이 점차 사라지는 것을 확인 할 수 있습니다. 어떻게 보면 좋은 현상으로는 보입니다. 하지만 여기서 문제는 상위 등급의 비율이 시간이 지나도 변하지 않는 것이 보입니다.
즉, 마케팅 대상을 상위 등급 고객들에 포커스를 맞추는 것이 좋을 것 같습니다.
저는 팀프로젝트를 하였을 때 RFM을 통해 등급을 기준으로 데이터가 어떻게 변화하는지만 보면 되는 것인 줄 알았으나, 해당 프로젝트를 해보면 RFM을 통해 무엇을 봐야 할 지(마지막 그래프에 해당하는 RFM 등급에 따른 이용 비중) 정확히 알 수 있었습니다.
그리고 RFM 분석에 대해서도 확실하게 이해하기 좋은 프로젝트였습니다.
이 글은 제로베이스 데이터 분석 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.
이상입니다.
'Project > data analysis' 카테고리의 다른 글
| [zero-base] 이커머스 고객 Segmentation을 위한 RFM 분석 - 1 (0) | 2024.11.21 |
|---|---|
| [zero-base] 셀프 주유소는 정말로 저렴한가? (보충) (0) | 2024.10.28 |
| [zero-base] 셀프 주유소는 정말로 저렴한가? (1) | 2024.10.25 |
| [zero-base] 스타벅스와 이디야 매장 거리 분석 (보충) (0) | 2024.10.23 |
| [zero-base] 스타벅스와 이디야 매장 거리 분석 (1) | 2024.10.22 |