RFM 분석하는 이유는?
고객별 RFM 3가지 지표들을 통해서 고객 점수 부여 및 등급화에 따른 서비스 등급을 부여합니다.
그리고 월마다 중요한 그룹에 대한 비중이 떨어지고 있는지 올라가고 있는지 확인 하는 것이 RFM 분석입니다.
즉, RFM 분석을 하게 되면 어떤 그룹에 타겟팅하여 마케팅할 지 정할 수 있게 됩니다.
1. 문제 정의
런칭 이후 서비스 정체기로 인한 영업이익, 사용 고객 수 감소
2. 해결방안
구매 데이터 활용 서비스 이용 현황 파악(지표 기획)
3. 기대 효과
정체 원인 파악 및 대응책 수립 및 실행을 통한 영업이익, 사용 고객 수 증가
🔈Process01
1. Data 전처리
1.1 Null값 확인
# ▶ Null 값 확인
print(df.isnull().sum())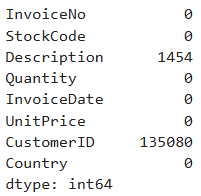
코드 결과를 보니 두 개의 컬럼 값에서 Nan값이 확인 되었습니다.
저는 CustomerID가 Nan값이면 알 수 있는 방법이 없기 때문에 삭제하도록 하겠습니다.
1.2 Null값 삭제
# ▶ null value drop
# ▶ CustomerID 기준으로 Null value drop
df.dropna(subset=['CustomerID'], how='all', inplace=True)
df.isnull().sum()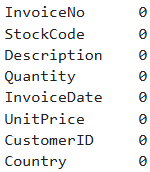
CustomerID의 값을 삭제한 결과 Description의 Nan값 또한 같이 사라진 것을 확인 할 수 있습니다.
1.3 Outlier 확인
df.describe()
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use(['dark_background'])
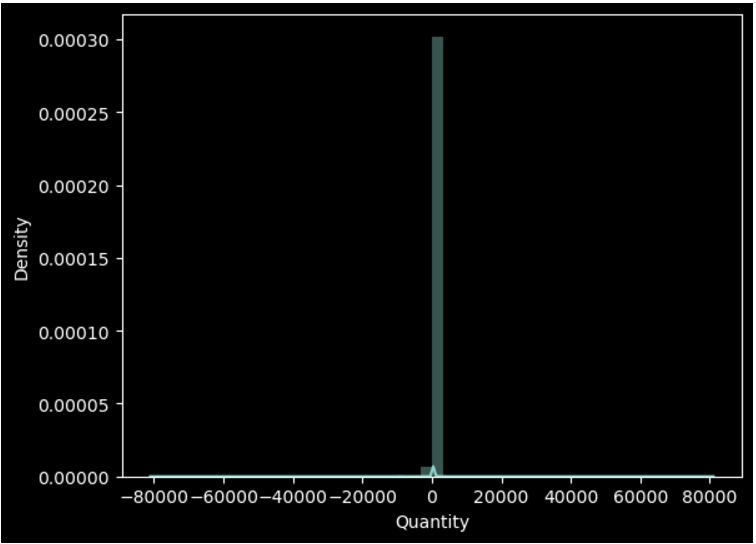
sns.distplot(df['Quantity'])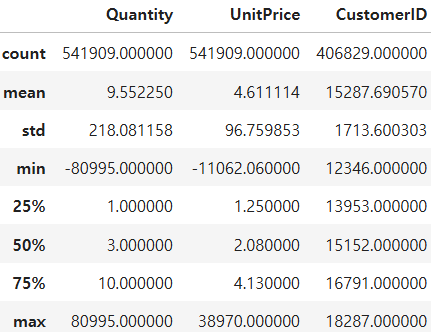
describe()를 통해 평균 최대값 최소값 사분위수 확인 결과 최소값에 이상하게도 Quantity와 UnitPrice의 컬럼값에 음수가 있는 것을 확인 할 수 있었습니다.
추가적으로 시각화 해본 결과 Outlier가 존재하는 것을 확인 할 수 있었습니다.
1.4 Outlier 삭제
df = df[df['UnitPrice']>0]
df = df[df['Quantity']>0]
df.describe()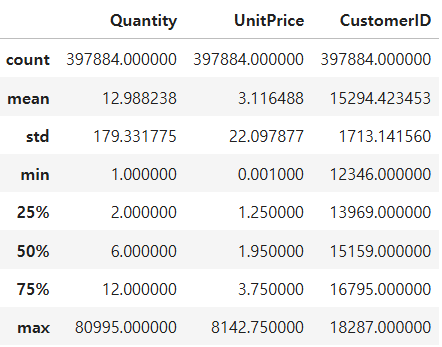
음수 값이 Outlier였으므로 0보다 큰 수만 가져오면 Outlier를 없앨 수 있습니다. 그리고 Outlier 제거 후 확인 결과 깔끔하게 Outlier는 없어진 것을 볼 수 있습니다.
1.5 고객수, 총 구매 수량, 국가 그리고 평균 구매 건수 확인
df['CustomerID'].nunique(), df['Quantity'].sum(), df['Country'].nunique()
df.groupby('CustomerID')['InvoiceNo'].count().mean()
이용 고객수는 4338, 총 구매 수량은 5,167,812개, 국가는 37개국입니다.
그리고 인당 평균 구매 건수는 약 91개로 확인 되었습니다.
🔈Process02
지표 기획 및 데이터 추출 -> RFM 구하기
Recency(최근성)
우선 며칠의 데이터가 있는지 확인 해본 결과 2010-12-01 ~ 2011-12-09일 까지 약 1년 정도의 데이터가 있는 것을 확인하였습니다.
2.1 고객들의 마지막 구매일 구하고 Recency 구하기
# ▶ 고객ID별 가장 마지막 구매일
recency_df = df.groupby('CustomerID',as_index=False)['Date'].max()
recency_df.columns = ['CustomerID','LastPurchaseDate']
# ▶ 고객의 가장 마지막 구매일로 부터 몇일이 지났는지를 계산하기 위함
recency_df['Recency'] = recency_df['LastPurchaseDate'].apply(lambda x : (df['Date'].max() - x).days)
recency_df.drop(columns=['LastPurchaseDate'],inplace=True)
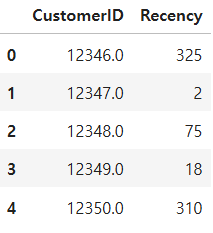
Recency를 구하기 위해 df['Date'].max()를 사용하여 가장 최근 날짜 기준을 구해줍니다. 그리고 고객들의 최근 구매를 빼주면 고객별 가장 마지막 구매일로 부터 며칠이 지났는지를 계산할 수 있습니다.
2.2 Recency 분포 확인
plt.style.use(['dark_background'])
sns.displot(data=recency_df, x="Recency")
plt.gcf().set_size_inches(16.5, 3)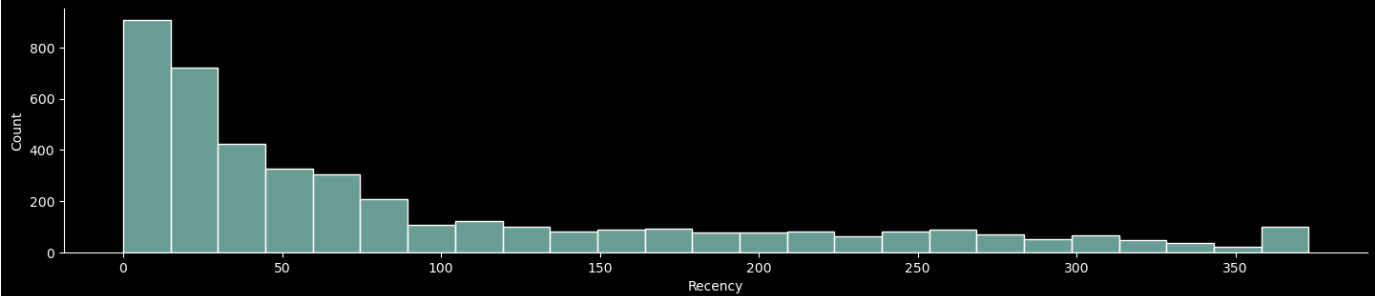
최근에 구매한 고객들이 매우 많은 것으로 확인 되었습니다.
2.3 Frequency(최빈성) 구하기
frequency_df = df.copy()
frequency_df.drop_duplicates(subset=['CustomerID', 'InvoiceNo'], keep='first', inplace=True)
frequency_df = frequency_df.groupby('CustomerID', as_index=False)['InvoiceNo'].count()
frequency_df.columns = ['CustomerID', 'Frequency']
frequency_df.head()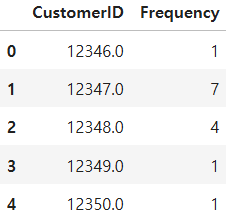
고객ID와 송장번호를 기준으로 중복되는 값이 있는 경우 첫 번째 값만 제외하고 모두 제거해주면 고객이 여러 물품을 구매했어도 하나의 주문으로 셀 수 있게 만들수 있습니다.
그리고 groupby를 통해 고객ID로 묶어준 뒤 송장번호 개수를 세주면 고객별 구매빈도를 확인할 수 있습니다.
2.4 Monetary(금액) 구하기
# ▶ 구매금액 = 구매개수 * 구매단가
df['Total_cost'] = df['UnitPrice'] * df['Quantity']
monetary_df=df.groupby('CustomerID',as_index=False)['Total_cost'].sum()
monetary_df.columns = ['CustomerID','Monetary']
monetary_df.head()구매 금액을 구하기위해 하나의 주문에 여러개의 수량일 수 있으므로 구매개수 * 구매 단가를 해줍니다.
그리고 고객ID를 groupby를 통해 묶어준 뒤 금액들을 모두 더해주면 고객별로 구매 금액을 측정할 수 있습니다.
2.5 RFM 테이블로 합쳐주기
# ▶ Data merge
# ▶ recency and frequency
rf = recency_df.merge(frequency_df,how='left',on='CustomerID')
# ▶ monetary
rfm = rf.merge(monetary_df,how='left',on='CustomerID')
rfm.head(5)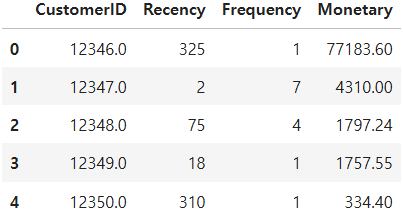
위에서 구한 R, F, M 테이블들을 고객ID를 기준으로 merge()해주면 테이블이 위의 이미지와 같이 깔끔하게 합쳐진 것을 볼 수 있습니다.
확실히 RFM을 또 공부하고 프로젝트를 시도해보니 훨씬 이해가 잘되고 깔끔하게 만들 수 있었습니다.
그리고 다음 글에서는 RFM을 이용하여 서비스 이용 수준 측정을 해볼 것입니다.
이 글은 제로베이스 데이터 분석 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.
이상입니다.
'Project > data analysis' 카테고리의 다른 글
| [zero-base] 이커머스 고객 Segmentation을 위한 RFM 분석 - 2 (1) | 2024.11.22 |
|---|---|
| [zero-base] 셀프 주유소는 정말로 저렴한가? (보충) (0) | 2024.10.28 |
| [zero-base] 셀프 주유소는 정말로 저렴한가? (1) | 2024.10.25 |
| [zero-base] 스타벅스와 이디야 매장 거리 분석 (보충) (0) | 2024.10.23 |
| [zero-base] 스타벅스와 이디야 매장 거리 분석 (1) | 2024.10.22 |
RFM 분석하는 이유는?
고객별 RFM 3가지 지표들을 통해서 고객 점수 부여 및 등급화에 따른 서비스 등급을 부여합니다.
그리고 월마다 중요한 그룹에 대한 비중이 떨어지고 있는지 올라가고 있는지 확인 하는 것이 RFM 분석입니다.
즉, RFM 분석을 하게 되면 어떤 그룹에 타겟팅하여 마케팅할 지 정할 수 있게 됩니다.
1. 문제 정의
런칭 이후 서비스 정체기로 인한 영업이익, 사용 고객 수 감소
2. 해결방안
구매 데이터 활용 서비스 이용 현황 파악(지표 기획)
3. 기대 효과
정체 원인 파악 및 대응책 수립 및 실행을 통한 영업이익, 사용 고객 수 증가
🔈Process01
1. Data 전처리
1.1 Null값 확인
# ▶ Null 값 확인
print(df.isnull().sum())코드 결과를 보니 두 개의 컬럼 값에서 Nan값이 확인 되었습니다.
저는 CustomerID가 Nan값이면 알 수 있는 방법이 없기 때문에 삭제하도록 하겠습니다.
1.2 Null값 삭제
# ▶ null value drop
# ▶ CustomerID 기준으로 Null value drop
df.dropna(subset=['CustomerID'], how='all', inplace=True)
df.isnull().sum()CustomerID의 값을 삭제한 결과 Description의 Nan값 또한 같이 사라진 것을 확인 할 수 있습니다.
1.3 Outlier 확인
df.describe()
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use(['dark_background'])
sns.distplot(df['Quantity'])describe()를 통해 평균 최대값 최소값 사분위수 확인 결과 최소값에 이상하게도 Quantity와 UnitPrice의 컬럼값에 음수가 있는 것을 확인 할 수 있었습니다.
추가적으로 시각화 해본 결과 Outlier가 존재하는 것을 확인 할 수 있었습니다.
1.4 Outlier 삭제
df = df[df['UnitPrice']>0]
df = df[df['Quantity']>0]
df.describe()음수 값이 Outlier였으므로 0보다 큰 수만 가져오면 Outlier를 없앨 수 있습니다. 그리고 Outlier 제거 후 확인 결과 깔끔하게 Outlier는 없어진 것을 볼 수 있습니다.
1.5 고객수, 총 구매 수량, 국가 그리고 평균 구매 건수 확인
df['CustomerID'].nunique(), df['Quantity'].sum(), df['Country'].nunique()
df.groupby('CustomerID')['InvoiceNo'].count().mean()
이용 고객수는 4338, 총 구매 수량은 5,167,812개, 국가는 37개국입니다.
그리고 인당 평균 구매 건수는 약 91개로 확인 되었습니다.
🔈Process02
지표 기획 및 데이터 추출 -> RFM 구하기
Recency(최근성)
우선 며칠의 데이터가 있는지 확인 해본 결과 2010-12-01 ~ 2011-12-09일 까지 약 1년 정도의 데이터가 있는 것을 확인하였습니다.
2.1 고객들의 마지막 구매일 구하고 Recency 구하기
# ▶ 고객ID별 가장 마지막 구매일
recency_df = df.groupby('CustomerID',as_index=False)['Date'].max()
recency_df.columns = ['CustomerID','LastPurchaseDate']
# ▶ 고객의 가장 마지막 구매일로 부터 몇일이 지났는지를 계산하기 위함
recency_df['Recency'] = recency_df['LastPurchaseDate'].apply(lambda x : (df['Date'].max() - x).days)
recency_df.drop(columns=['LastPurchaseDate'],inplace=True)
Recency를 구하기 위해 df['Date'].max()를 사용하여 가장 최근 날짜 기준을 구해줍니다. 그리고 고객들의 최근 구매를 빼주면 고객별 가장 마지막 구매일로 부터 며칠이 지났는지를 계산할 수 있습니다.
2.2 Recency 분포 확인
plt.style.use(['dark_background'])
sns.displot(data=recency_df, x="Recency")
plt.gcf().set_size_inches(16.5, 3)최근에 구매한 고객들이 매우 많은 것으로 확인 되었습니다.
2.3 Frequency(최빈성) 구하기
frequency_df = df.copy()
frequency_df.drop_duplicates(subset=['CustomerID', 'InvoiceNo'], keep='first', inplace=True)
frequency_df = frequency_df.groupby('CustomerID', as_index=False)['InvoiceNo'].count()
frequency_df.columns = ['CustomerID', 'Frequency']
frequency_df.head()고객ID와 송장번호를 기준으로 중복되는 값이 있는 경우 첫 번째 값만 제외하고 모두 제거해주면 고객이 여러 물품을 구매했어도 하나의 주문으로 셀 수 있게 만들수 있습니다.
그리고 groupby를 통해 고객ID로 묶어준 뒤 송장번호 개수를 세주면 고객별 구매빈도를 확인할 수 있습니다.
2.4 Monetary(금액) 구하기
# ▶ 구매금액 = 구매개수 * 구매단가
df['Total_cost'] = df['UnitPrice'] * df['Quantity']
monetary_df=df.groupby('CustomerID',as_index=False)['Total_cost'].sum()
monetary_df.columns = ['CustomerID','Monetary']
monetary_df.head()구매 금액을 구하기위해 하나의 주문에 여러개의 수량일 수 있으므로 구매개수 * 구매 단가를 해줍니다.
그리고 고객ID를 groupby를 통해 묶어준 뒤 금액들을 모두 더해주면 고객별로 구매 금액을 측정할 수 있습니다.
2.5 RFM 테이블로 합쳐주기
# ▶ Data merge
# ▶ recency and frequency
rf = recency_df.merge(frequency_df,how='left',on='CustomerID')
# ▶ monetary
rfm = rf.merge(monetary_df,how='left',on='CustomerID')
rfm.head(5)위에서 구한 R, F, M 테이블들을 고객ID를 기준으로 merge()해주면 테이블이 위의 이미지와 같이 깔끔하게 합쳐진 것을 볼 수 있습니다.
확실히 RFM을 또 공부하고 프로젝트를 시도해보니 훨씬 이해가 잘되고 깔끔하게 만들 수 있었습니다.
그리고 다음 글에서는 RFM을 이용하여 서비스 이용 수준 측정을 해볼 것입니다.
이 글은 제로베이스 데이터 분석 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.
이상입니다.
'Project > data analysis' 카테고리의 다른 글
| [zero-base] 이커머스 고객 Segmentation을 위한 RFM 분석 - 2 (1) | 2024.11.22 |
|---|---|
| [zero-base] 셀프 주유소는 정말로 저렴한가? (보충) (0) | 2024.10.28 |
| [zero-base] 셀프 주유소는 정말로 저렴한가? (1) | 2024.10.25 |
| [zero-base] 스타벅스와 이디야 매장 거리 분석 (보충) (0) | 2024.10.23 |
| [zero-base] 스타벅스와 이디야 매장 거리 분석 (1) | 2024.10.22 |